在本 PHP 教程中,您将学习有关 PHP 中 XML 的所有内容。我们将详细讨论 XML 的类型、XML 解析扩展等。
XML 是可扩展标记语言的缩写。XML 是一种用于在 Web 上传输数据的标记语言。它既是人类可读的,也是机器可读的。RSS Feed 是可共享 XML 的一个例子。XML 解析器对于在 Web 浏览器中读取和更新数据很重要。
SOAP 和 REST 等 Web 服务以 XML 格式交换数据。由于当前应用程序严重依赖 Web 服务,因此了解 XML 是什么以及它是如何工作的,可以为您作为开发人员带来竞争优势。XML 文档可用于保存应用程序的配置文件。它允许您构建自己的标签,使其更具多功能性。
XML 解析器是一种将 XML 文档转换为 XML 文档对象模型 (DOM) 对象的程序。然后,XML DOM 对象可以使用 JavaScript、Python 和 PHP 等语言进行处理。在解析 XML 文档时,CDATA 这个术语(表示未解析的字符数据)用于排除特殊字符,如“<”、“>”。
基于树的解析器将整个文本保存在内存中,并将其转换为树结构。它分析整个文档,并允许您访问树元素 (DOM)。这种类型的解析器适用于较小的 XML 文档;但是,由于性能限制,它不适用于大型 XML 文档。
基于树的解析器的示例是
基于事件的解析器不将整个文本保存在内存中,而是一次读取一个节点,并允许实时与之交互。当您移到下一个节点时,前一个节点将被删除。这种类型的解析器非常适合大型 XML 文档。它解析速度更快,内存占用更少。
基于事件的解析器的示例是
XML 解析扩展是基于 libxml 工作的。PHP 核心包含以下 XML 解析器。
Simple XML 解析器,也称为基于树的 XML 解析器,可以解析简单的 XML 文件。要从给定位置获取 XML,Simple XML 解析器将调用 simplexml_load_file() 函数。
DOM 解析器,也称为复杂节点解析器,用于读取非常复杂的 XML 文件。它充当编辑 XML 文件的接口。DOM 解析器使用了 UTF-8 字符编码。
SAX 解析是 XML 解析的基础。所有之前的解析器都比较慢。它将生成和解析 XML 文件。XML 解析器使用的字符编码包括 ISO-8859-1、US-ASCII 和 UTF-8 字符编码。
Pull XML 解析是 XML Reader 解析的另一个术语。它用于更快地读取 XML 文件。它使用 XML 验证支持高度复杂的 XML 文档。
如果您知道 XML 文档的结构或布局,SimpleXML 可以轻松获取元素的名称、属性和文本内容。SimpleXML 将 XML 文本转换为可以迭代的数据结构,类似于数组或对象的集合。与 DOM 或 Expat 解析器相比,SimpleXML 读取元素中文本数据所需的代码行更少。
Simple XML 解析器中最常用的函数是
<?xml version = "1.0" encoding="UTF-8"?>
<data>
<to>John</to>
<from>Jane</from>
<heading>Reminder</heading>
<body>Don't forget the party!</body>
</data>
<?php
$xml = simplexml_load_file("datas.xml") or die("Error: Cannot create object");
print_r($xml);
?>
输出
SimpleXMLElement Object
(
[to] => John
[from] => Jane
[heading] => Reminder
[body] => Don't forget the party!
)
<?php $myXMLData = "<?xml version = '1.0' encoding='UTF-8'?>
<data>
<to>John</to>
<from>Jane</from>
<heading>Reminder</heading>
<body>Don't forget the party!</body>
</data>";
$xml = simplexml_load_string($myXMLData) or die("Error: Cannot create object");
print_r($xml);?>
输出
SimpleXMLElement Object
(
[to] => John
[from] => Jane
[heading] => Reminder
[body] => Don't forget the party!
)
<?php
$dom = new domDocument;
$dom->loadXML("<data>
<to>John</to>
<from>Jane</from>
<heading>Reminder</heading>
<body>Don't forget the party!</body>
</data>");
$x = simplexml_import_dom($dom);
echo $x->body;
?>
输出
Don't forget the party!
使用 XML Get 可以从 XML 文件中获取节点值。下面的示例演示了如何从 XML 中获取数据。
<?xml version = "1.0" encoding="UTF-8"?>
<data>
<to>John</to>
<from>Jane</from>
<heading>Reminder</heading>
<body>Don't forget the party!</body>
</data>
<!DOCTYPE html>
<html>
<body>
<?php
$xml = simplexml_load_file("datas.xml") or die("Error: Cannot create object");
echo $xml->to . "<br>";
echo $xml->from . "<br>";
echo $xml->heading . "<br>";
echo $xml->body;
?>
</body>
</html>
输出
John Jane Reminder Don't forget the party!
SAX 解析器用于解析 XML 文件,并且在内存管理方面优于示例 XML 解析器和 DOM。由于它不将任何数据保存在内存中,因此它可以处理非常大的文件。以下示例将演示如何使用 SAX API 从 XML 中提取数据。
<?xml version = "1.0" encoding = "utf-8"?>
<students>
<course>
<name>Android</name>
<country>India</country>
<phone>123456789</phone>
</course>
<course>
<name>Java</name>
<country>India</country>
<phone>123456789</phone>
</course>
<course>
<name>HTML</name>
<country>India</country>
<phone>123456789</phone>
</course>
</students>
<?php
$students = array();
$elements = null;
function startElements($parser, $name, $attrs)
{
global $students, $elements;
if (!empty($name)) {
if ($name == 'COURSE') {
$students[] = array();
}
$elements = $name;
}
}
function endElements($parser, $name)
{
global $elements;
if (!empty($name)) {
$elements = null;
}
}
function characterData($parser, $data)
{
global $students, $elements;
if (!empty($data)) {
if ($elements == 'NAME' || $elements == 'COUNTRY' || $elements == 'PHONE') {
$students[count($students) - 1][$elements] = trim($data);
}
}
}
$parser = xml_parser_create();
xml_set_element_handler($parser, "startElements", "endElements");
xml_set_character_data_handler($parser, "characterData");
if (!($handle = fopen('datas.xml', "r"))) {
die("could not open XML input");
}
while ($data = fread($handle, 4096)) {
xml_parse($parser, $data);
}
xml_parser_free($parser);
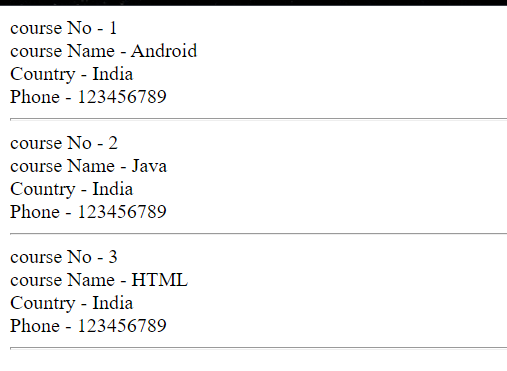
$i = 1;
foreach ($students as $course) {
echo "course No - " . $i . '<br/>';
echo "course Name - " . $course['NAME'] . '<br/>';
echo "Country - " . $course['COUNTRY'] . '<br/>';
echo "Phone - " . $course['PHONE'] . '<hr/>';
$i++; } ?>
输出
DOM 解析器在处理 XML 和 HTML 方面都很高效。DOM 解析器以基于树的方式进行遍历,在访问数据之前,它会将数据加载到 DOM 对象中,并在 Web 浏览器中更新数据。下面的示例演示了如何在 Web 浏览器中访问 HTML 数据。
<?php
$html = '
<head>
<title>Xml Demo</title>
</head>
<body>
<h2>Course details</h2>
<table border = "0">
<tbody>
<tr>
<td>Python</td>
<td>3 Month</td>
<td>learnetutorials.com</td>
</tr>
<tr>
<td>PHP</td>
<td>3 Month</td>
<td>learnetutorials.com</td>
</tr>
<tr>
<td>JAVA</td>
<td>3 Month</td>
<td>learnetutorials.com</td>
</tr>
<tr>
<td>JavaScript</td>
<td>3 Month</td>
<td>learnetutorials.com</td>
</tr>
</tbody>
</table>
</body>
</html>
';
$dom = new domDocument;
$dom->loadHTML($html);
$dom->preserveWhiteSpace = false;
$tables = $dom->getElementsByTagName('table');
$rows = $tables->item(0)->getElementsByTagName('tr');
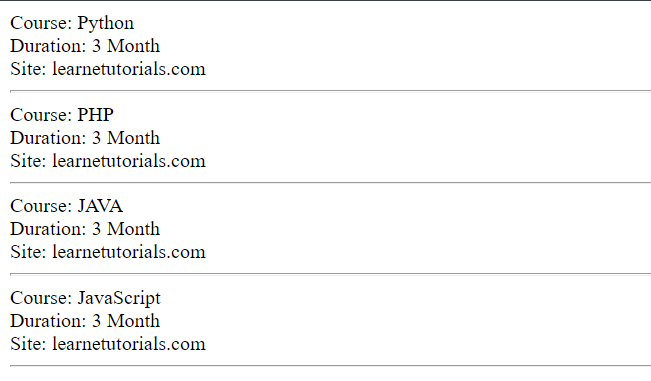
foreach ($rows as $row) {
$cols = $row->getElementsByTagName('td');
echo 'Course: ' . $cols->item(0)->nodeValue . '
';
echo 'Duration: ' . $cols->item(1)->nodeValue . '
';
echo 'Site: ' . $cols->item(2)->nodeValue;
echo '<hr />';} ?>