

在本教程中,您将掌握关于Python模块和Python包的所有知识,这两种编程技术可以简化模块化编程。还将介绍如何重新加载模块、如何从包中导入模块等主题,并附有示例。
模块化编程是一种在软件编程中使用的设计技术。它强调将大型程序分解为离散的、微小的、兼容的子程序或模块的技术。模块化方法为程序提供了以下好处。
提升模块化的 Python 结构包括函数、模块和包。在上一个教程中,我们已经学习了关于Python函数的所有知识。
模块是一个简单的文件,包含定义和可执行语句。创建 Python 模块并不难。您需要做的就是
例如,在下面的示例中,mymod.py 是一个模块,它有一个变量 L 和两个函数 prt() 和 sum()。
L=['Red','Green','Blue']
print('Colour List is',L)
def prt(name):
print('Hello',name)
def sum(a,b):
total = a+b
print(total)
一个模块可以包含多个对象,如变量、函数、类等。
可以使用关键字 import 将模块访问到另一个模块或交互式解释器中。下面的示例展示了如何导入我们之前定义的模块。
import mymod #imports the module mymod.py
相应地,我们也可以导入 Python 中存在的内置模块。在此之前,让我们先了解如何检查 Python 中可用的内置模块列表。要获取内置模块的列表,请使用下面示例中的任一方法。
>>> import sys
>>> print(sys.builtin_module_names)
Or
>>> help('modules')
输出将是 Python 中内置模块的列表,如下所示。
('_abc', '_ast', '_bisect', '_blake2', '_codecs', '_codecs_cn', '_codecs_hk', '_codecs_iso2022', '_codecs_jp', '_codecs_kr', '_codecs_tw', '_collections', '_contextvars', '_csv', '_datetime', '_functools', '_heapq', '_imp', '_io', '_json', '_locale', '_lsprof', '_md5', '_multibytecodec', '_opcode', '_operator', '_pickle', '_random', '_sha1', '_sha256', '_sha3', '_sha512', '_signal', '_sre', '_stat', '_statistics', '_string', '_struct', '_symtable', '_thread', '_tracemalloc', '_warnings', '_weakref', '_winapi', '_xxsubinterpreters', 'array', 'atexit', 'audioop', 'binascii', 'builtins', 'cmath', 'errno', 'faulthandler', 'gc', 'itertools', 'marshal', 'math', 'mmap', 'msvcrt', 'nt', 'parser', 'sys', 'time', 'winreg', 'xxsubtype', 'zlib')
要访问模块中的内容或对象,我们使用点运算符 (.)。现在,让我们看看如何使用点运算符从我们之前定义的模块 mymod.py 中导入内容。
>>> import mymod #imports the module mymod
>>> mymod.prt('Chris') #imports the function prt in module mymod
Hello Chris
>>> mymod.sum(10,20) #imports the function sum in module mymod
30
接下来,我们将学习导入模块及其内容的几种其他方法。
使用关键字 import 和 点运算符,我们也可以像用户定义函数一样导入 Python 中的内置函数。下面的示例展示了 import 语句的用法。
import math
print('Factorial of 5 is :',math.factorial(5))
Factorial of 5 is : 120
在这个示例中,内置模块 math 被导入,并且它的对象 pi 使用点运算符进行访问。
导入模块后也可以重命名模块,并使用该名称来访问其内容。下面的示例展示了模块的重命名。
import math as X
print('Factorial of 5 is :',X.factorial(5))
Factorial of 5 is : 120
在这里,模块 math 被重命名为 X,我们使用 X 来访问对象 pi。
导入内容的另一种方法是在一行中指定内容和模块的名称。在这里,我们不需要点运算符来导入内容。
from math import factorial
print('Factorial of 5 is :',factorial(5))
Factorial of 5 is : 120
这个例子告诉我们,模块对象 pi 是从模块 math 中导入的。
假设您需要从同一模块导入多个内容。在这种情况下,from...import* 是完美的解决方案。在这里,我们可以访问模块中的所有定义。* 表示访问模块中所有可用的内容或定义。
from math import *
print('Factorial of 5 is :',factorial(5))
Factorial of 5 is : 120
虽然这是导入定义的一种简单方法,但它并不是最佳编程实践,因为它会影响代码的可读性。
我们现在熟悉了从模块导入内容的各种方法,那么一旦导入模块,解释器会做什么?解释器首先会检查模块是否在内置模块中可用。如果找不到,那么 Python 将搜索 sys.path 中定义的系统搜索路径,其中包含目录列表。
下面的示例让您了解 sys.path
import sys
print(sys.path)
['', 'C:\\Users\\Programs\\Python\\Python38-32\\Lib\\idlelib', 'C:\\Users\\Programs\\Python\\Python38-32\\python38.zip', 'C:\\Users\\Programs\\Python\\Python38-32\\DLLs', 'C:\\Users\\Programs\\Python\\Python38-32\\lib', 'C:\\Users\\Programs\\Python\\Python38-32', 'C:\\Users\\Programs\\Python\\Python38-32\\lib\\site-packages']
搜索遵循以下顺序。
有时您在尝试导入用户定义的模块时可能会遇到错误。原因是文件的位置不正确。因此,您必须确保模块文件放置在上述三个位置中的任何一个(当前目录、python 路径或默认路径)。
导入模块后,您还可以使用 file 属性发现模块的位置。
import mymod
mymod.__file__
'C:\\Users\\Programs\\Python\\Python38-32\\mymod.py'
dir() 是一个 Python 内置函数,它返回命名空间中已定义名称的字母顺序排序列表。此列表包含包含在模块中的所有模块(内置和用户定义的)、变量和函数。下面的示例给出了 dir() 函数用法的实例。
import mymod
dir(mymod)
['L', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'prt', 'sum']
这里,以划线开头的名称是模块中的默认属性。例如,__name__ 属性提供模块的名称。L、prt、sum 是 mymod 模块中的对象或用户定义的属性。
关于模块的一个重要说明是,Python 在每个解释器会话中只导入模块一次。让我们来理解下面的例子。
import mymod
Colour List is ['Red', 'Green', 'Blue']
import mymod
import mymod
在上面的示例中,您可以发现可执行语句仅执行一次,并且后续导入中的 print 语句不会被忽略。这表明一个模块只导入一次。
如果您更改了模块内容,或者您想重新执行该语句,您可以重新启动 Python 解释器或使用 reload() 函数。reload 函数位于module importlib 中,因此您需要先导入它。
语法如下所示。
reload(module_name)
其中 module_name 是您希望重新加载的模块的名称。如下面的示例所示,print 语句在重新加载后执行。
import importlib
importlib.reload(mymod)
Colour List is ['Red', 'Green', 'Blue']
到目前为止,您已经了解了什么是模块以及如何导入模块及其中的对象。现在我们将了解包,它将帮助我们以结构化的方式组织应用程序的代码。
简单来说,包就是模块或包本身的集合。包中的包称为子包。包有助于以组织良好的方式存储目录和模块,最好是分层结构。随着应用程序规模的增大和许多模块的使用,这将有助于在导入时提高效率。
我们可以将相似的模块存储在一个包中,将不同的模块存储在另一个包中。这样做有助于避免包内模块之间的冲突以及模块内全局变量之间的冲突。
创建一个包就像在计算机上创建文件夹一样简单。我们会有一个包含子文件夹和文件的主要文件夹。类似地,一个包包含子包和模块。下面的可视化是包“P”的示例,它有两个子包 sp1 和 sp2。sp1 包含两个模块 m1 和 m2,而 sp2 包含模块 m3。
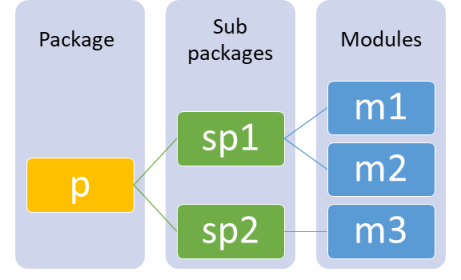
下面展示了导入包中子包和模块的不同方法。我们所需要的只是使用点表示法来导入包内的模块或子包。
import p # imports package P
import p.sp1,p.sp2 # imports subpackages from package P
import p.sp1.m1,p.sp2 # imports modules in subpackages
import p.sp1.m2 as X
from p.sp1.m2 import object # imports contents in a module
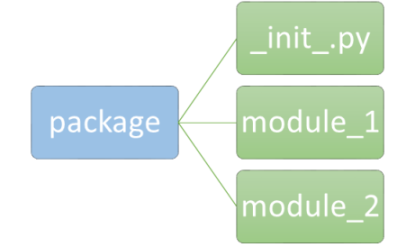
当一个目录包含名为 _init_ 的文件时,Python 将该目录视为一个包。字面上说, _init_.py 用于初始化包对象或全局变量。这个文件也可以是空的。包的通用形式在下图所示。
我们已经看到了从包导入模块的通用语法。让我们详细说明一下,以便为您提供清晰的概念。为此,我们修改了 mymod 模块示例为一个包,并看看包如何帮助模块化编程。
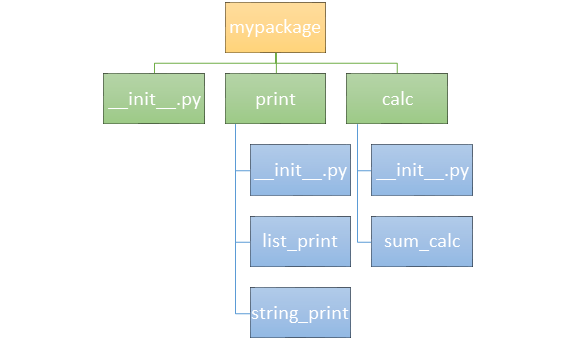
我们有一个名为“mypackage”的包,它包含 __init__.py 文件和两个子文件夹 - print 和 calc。每个子包都包含模块。Print 子包包含两个模块,即:
而 calc 子包包含 __init__.py 文件和一个名为 sum_calc 的函数,该函数执行两个数字的加法。
上面示例的可视化如下所示。
现在让我们看看这些模块里面有什么。
L=['Red','Green','Blue']
print('Colour List is',L)
def prt(name):
print('Hello',name)
def sum(a,b):
total = a+b
print('Total is :',total)
import mypackage.print.list_print.L
Colour List is ['Red', 'Green', 'Blue']
import mypackage.print.String_print as X
X.prt(‘Chris’)
Hello,Chris
from mypackage.print import sum_calc
sum_calc.sum(10,20)
Total is :30
我们遇到了 module*,它表示我们可以访问模块中的所有定义。同样,我们可以使用 * 表示法访问包中的所有模块,但要记住的是,它必须在 __init__.py 文件中包含一个名为 __all__ 的列表。当遇到 from 语句
注意:当未定义 __all__ 时,import * 不会从包中导入任何内容,而会导入模块中的所有内容。

