

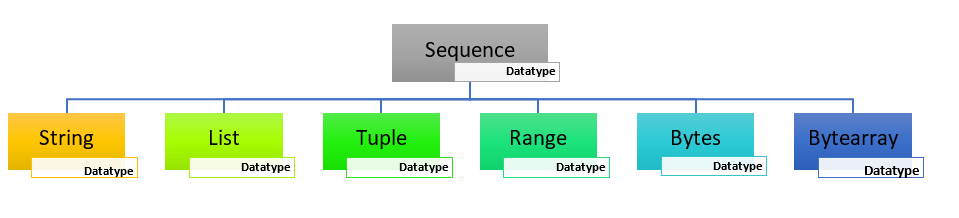
在本教程中,您将学习什么是序列数据类型及其分类,以及在Python编程语言中的各种操作。
在Python编程语言中,序列数据类型是除数字、映射、实例和异常之外的基本内置数据类型之一。
序列可以定义为按特定顺序排列的对象集合,其中每个对象都跟随另一个对象。
Python有六种序列数据类型——字符串、列表、元组、范围、字节、字节数组。其中,最重要的序列数据类型是字符串、列表和元组。
在编程中,字符序列称为字符串。
字符可以是字母、数字、符号、空格或标点符号。任何可以在计算机上输入的(可见或不可见的)内容都被视为字符。例如,Python是一个由六个字符组成的字符串,所有字符都是字母。
计算机作为机器,不像人类那样总是理解二进制语言,即0或1。更具体地说,用户可读的字符必须转换为机器语言。在计算机中,屏幕上出现的每一个字符都被隐式地转换为由0和1组成的二进制组合。这种转换称为编码,而二进制到字符的转换称为解码。两个普遍接受的编码标准是ASCII和Unicode。
在Python编程语言中,字符串是Unicode字符的有序序列。字符串的一个重要特性是它的不可变性,这意味着在创建字符串后无法更改其状态。
Python字符串通过将文本或字符括在双引号(“……”)或单引号(‘……’)中来定义。
Str1 = 'Hello'
Str2 = "Welcome"
print(Str1)
print(Str2)
输出
Hello Welcome
在Python字符串中,三引号用于表示多行字符串。我们可以使用三个连续的单引号(‘‘‘…….’’’)或三个连续的双引号(“””……”””)来跨越多行。
Str3 = '''...
Python programming Language
multiline in three single quotes
... '''
Str4 =""".....
Multiline string example
in three double quotes
....."""
print(Str3)
print(Str4)
输出
... Python programming Language multiline in three single quotes ... ..... Multiline string example in three double quotes .....
Python,与其他编程语言类似,也将字符串视为Unicode字符的数组。我们可以使用索引或切片单独或集体地访问字符。
索引是为序列中的字符编号以方便查找的过程。索引必须始终为整数。
由于字符串是Unicode字符的序列,每个字符位置都像数组一样用相应的数字进行索引。Python中有两种索引方式:
例如,
PYTHON 是一个字符串,其字符数组为 P、Y、T、H、O 和 N。字符串的长度为6。字符串PYTHON 的正向和反向索引在下表中可视化。
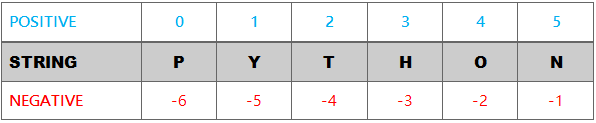
通过索引号,我们可以使用索引运算符[ ]轻松地单独访问字符。下面的示例显示了通过正向索引提取单个字符。
S = 'PYTHON'
print('S[0] = ',S[0])
print('S[4] = ',S[4])
输出
S[0] = P S[4] = O
假设我们有一个长字符串并想定位末尾的字符。Python支持从尾部到头部的倒数计数。反向索引总是从-1开始。
S = 'PYTHON'
print('S[-1] = ',S[-1])
print('S[-5] = ',S[-5])
输出
S[-1] = N S[-5] = Y
在Python中使用索引时,常见的两种错误是:
TypeError。IndexError。S = 'PYTHON'
print('s[4.5] = ',s[4.5]) #Exibits typeerror as index is a float value
print('s[41] = ',s[41]) #Exibits Indexerror is out of length
输出
print('s[4.5] = ',s[4.5])
TypeError: string indices must be integers
print('s[41] = ',s[41])
IndexError: string index out of range
到目前为止,我们已经讨论了如何使用索引运算符[]从字符串中访问单个字符。我们还可以使用范围切片运算符[:]从字符串中集体提取字符。
切片顾名思义,将序列切成一系列片段。在Python字符串中,索引或切片运算符[]用于访问长度为1的子字符串,而范围切片运算符[:]用于访问字符块或任意长度的子字符串。
范围切片的语法可以表示为:
S[m : n]
其中,
S:字符串
m:起始索引
n:结束索引
S[m:n]返回从索引m到n的子字符串,但不包括索引n。
为了更好地理解,请看下面的范围切片可视化。每个字符都放置在索引之间。例如,字符 P 位于 0 和 1 之间,'PY' 位于 0 和 2 之间。
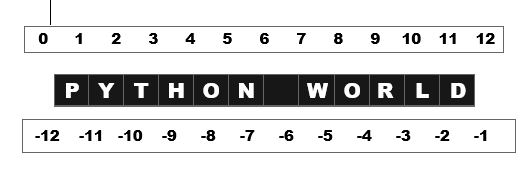
下表更清晰地展示了Python中正向索引切片的概念
| 切片表达式 | 子字符串长度 | 输出 | 备注 |
|---|---|---|---|
| S[0:5] | 5 | python | 返回从索引0到4的字符;不包含位置5 |
| S[0:6] | 6 | python | 返回从索引0到5的字符,不包括6 |
| S[7:11] | 4 | worl | 返回 |
| S[6:12] | 6 | w,o,r,l,d | 省略了索引12 |
| S[: 8] | 8 | python w | 默认从开头开始,省略索引8 |
| S[8:] | 4 | orld | 默认计数到尾部 |
S ="python world"
print("S[0:5] = ",S[0:5])
print("S[0:6] = ",S[0:6])
print("S[7:11] = ",S[7:11])
print("S[6:12] = ",S[6:12])
print("S[:8] = ",S[:8])
print("S[8:] = ",S[8:])
输出
S[0:5] = pytho S[0:6] = python S[7:11] = worl S[6:12] = world S[:8] = python w S[8:] = orld
下表更清晰地展示了Python中反向索引切片的概念
| 切片表达式 | 子字符串长度 | 输出 | 备注 |
|---|---|---|---|
| S[-12:-7] | 5 | pytho | 返回从位置-12到-7的字符,省略位置-7 |
| S[-7:-3] | 4 | n wo | 返回从位置-7到-3的字符,省略位置-3 |
| S[-12:] | 12 | python world | 默认从尾部计数到末尾 |
| S[:-7] | 5 | pytho | 默认从位置-8到开头计数 |
S ="python world"
print("S[-12:-7] = ",S[-12:-7])
print("S[-7:-3] = ",S[-7:-3])
print("S[-12:] = ",S[-12:])
print("S[:-7] = ",S[:-7])
输出
S[-12:-7] = pytho S[-7:-3] = wo S[-12:] = python world S[:-7] = pytho
字符串的一个特殊特性是其不可变性。一旦字符串被赋给一个变量,我们就不能修改它。但是,我们可以通过将变量重新赋给另一个字符串来更新字符串。
V = 'Python World'
print('Initially Variable V is assigned to :',V)
V = ' Python programming'
print("Variable V is reassigned to :",V)
输出
Initially Variable V is assigned to : Python World Variable V is reassigned to : Python programming
同样,我们可以使用关键字“del”删除整个字符串,但从字符串中删除字符在Python编程语言中不是有效操作。删除字符串的语法如下:
del 变量名
V = 'Python World'
del V
print (V)
输出:错误
print('V =',V)
NameError: name 'V' is not defined
Python有几种内置函数可以执行字符串的特定任务。最常用的字符串函数是len()。除了len()之外,enumerate()函数也被广泛使用,我们将在后面的教程中讨论。
len()函数通过计算字符串中字符的数量来给出字符串的长度。
#String Function
str ='Python World'
print('Length of the string is',len(str))
输出
Length of the string is 12
Python允许字符串执行各种操作。由于每个操作都是唯一的,因此它们有独特设计的运算符。本节将解释字符串中最重要和最常见的运算符。
成员资格运算符用于验证子字符串在字符串中的存在。结果将是True或False。如果子字符串存在,则返回真值True,否则返回False。Python中有两种类型的成员资格运算符。它们是:
#Membership operator
str = 'Python Member'
A ='M' in str
B='Me' not in str
print(A)
print(B)
输出
True False
字符串的基本操作之一是连接。连接是指将两个或多个字符串粘合在一起形成一个新字符串。Python中的连接运算符是“+”加号。请注意,在数字的情况下,加号用于加法,而在字符串中,它充当字符串连接符。
#String Concatenation using +
s1 = 'Python'
s2 = 'World'
print('String after concatenation :',s1+s2)
输出
String after concatenation : PythonWorld
类似地,使用*符号,我们可以多次重复连接字符串。
#String Concatenation using *
s1 = 'Python'
print('s1*3 =',s1*3)
输出
s1*3 = PythonPythonPython
注意:由于字符串是不可变的,因此连接后形成的新字符串需要赋给一个新变量才能存储它。
需要注意的下一个事实是,在Python编程语言中,无法进行隐式字符串转换。因此,将字符串与数字、布尔值等非字符串类型连接将导致TypeError。
s1 = 'Python'
print( s1+3)
输出
print( s1+3) TypeError: can only concatenate str (not "int") to str
注意:Python只能连接字符串到字符串
让我们回顾一下,在Python中,字符串是用单引号或双引号分隔的。当尝试打印纯文本,例如 It’s a “python program” 时,其中已包含双引号,会发生什么?当文本被解释时,会发生表示语法错误的SyntaxError。
解决此问题的一种方法是使用三引号——三个连续的单引号或三个连续的双引号。另一个选项是使用转义字符。
转义字符,顾名思义,可以转义字符串中的特殊字符,如单引号或双引号。反斜杠(\)在Python字符串中被认为是转义字符。换句话说,转义字符允许您将特殊字符转换为普通字符。
例如:
It\’s a \ “python program\” 在Python中等同于 It’s a “python program”。在此示例中,每个特殊字符都用反斜杠前缀,以规避SyntaxError,从而允许在文本中打印特殊字符。
#String formatting
print('''it's a "python program"!!!''') #Triple Quotes
print('it\'s a \"python program\"!!!') #Escape Character
输出
#String formatting
print('''it's a "python program"!!!''') #Triple Quotes
print('it\'s a \"python program\"!!!') #Escape Character
反斜杠还用于表示某些空白字符,如制表符、换行符、空格、回车符等。
print('Straw\tBerry')
print("Mul\nBerry")
输出
Straw Berry Mul Berry
以下是Python中额外的转义字符列表。
| 转义格式 | 说明 |
|---|---|
| \’ | 单引号 |
| \” | 双引号 |
| \n | 换行符或行馈送 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \r | 回车符 |
| \b | 退格符 |
| \a | 响铃 |
| \f | 换页符 |
| \\ | \ |
| \ooo | ASCII八进制值 ooo |
| \xhh | ASCII十六进制值 hh |
Python的另一个独特特性是通过原始字符串的表示将转义字符视为普通字符的能力。原始字符串只是以'r'或'R'开头的大小写普通的字符串字面量。与转义序列不同,当遇到原始字符串时,反斜杠没有特殊含义。
#Raw StringExample
print("Hi\tWelcome To \n PYTHON \x48 WORLD! ")
print(R"Hi\tWelcome To \n PYTHON \xWORLD! ")
输出
Hi Welcome To PYTHON H WORLD! Hi\tWelcome To \n PYTHON \xWORLD!
为了清楚地理解原始字符串,让我们仔细研究上面的示例。在上面的示例中,第一个字符串包含3个转义字符——\t、\n和\x48,它们分别表示制表符、换行符和十六进制表示。您可以看到相应的结果。第二个字符串被标记为原始字符串,并且还包含3个转义字符——\t、\n和\x。在这里,\x没有特定的表示或含义。即使如此,程序也能成功打印字符串而不会引发任何错误。这是因为原始字符串会忽略字符串字面量中的所有转义字符。但是,如果字符串未标记为原始字符串,情况则不同。它将引发如下所示的错误。
print("Hi\tWelcome To \n PYTHON \x WORLD! ")
^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 25-26: truncated \xXX escape
为了高效地操作字符串,Python提供了一套广泛的内置方法,如下表所示。
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | capitalize() | 大写字符串的第一个字母 |
| 2 | center(width,fillchar) | 返回一个带有空格填充的字符串,其中原始字符串居中。 |
| 3 | count(str, beg, end) | 计算字符串或字符串子串中str的出现次数,如果给定了起始索引beg和结束索引end。 |
| 4 | decode(encoding,errors) | 使用为编码注册的编解码器解码字符串。 |
| 5 | encode(encoding,errors) | 返回字符串的编码字符串版本;当遇到错误时引发ValueError。 |
| 6 | endswith(suffix, beg, end) | 如果字符串或字符串的子串(如果给定了起始索引beg和结束索引end)以suffix结尾,则确定并返回True;否则返回False。 |
| 7 | expandtabs(tabsize) | 将字符串中的制表符扩展为空格;默认情况下,制表符大小扩展到8个空格。 |
| 8 | find(str, beg, end) | 如果str存在于字符串或其子字符串中,则返回str的索引,否则返回-1。 |
| 9 | index(str, beg, end) | 返回与find()相同的索引,但如果未找到str,则引发异常。 |
| 10 | isalnum() | 如果字符串至少包含一个字母数字字符,则返回True;否则返回False。 |
| 11 | isalpha() | 如果字符串至少包含一个字母字符,则返回True;否则返回False。 |
| 12 | isdigit() | 仅当字符串包含数字时才返回True;否则返回False。 |
| 13 | islower() | 如果字符串至少包含一个小写字母,则返回True;否则返回False。 |
| 14 | isnumeric() | 如果Unicode字符串仅包含数字字符,则返回True;否则返回False。 |
| 15 | isspace() | 如果字符串包含空格字符,则返回True;否则返回False。 |
| 16 | istitle() | 如果字符串被正确地“首字母大写”,则返回True;否则返回False。 |
| 17 | isupper() | 如果字符串至少包含一个大写字符,则返回True;否则返回False。 |
| 18 | join() | 连接多个字符串。 |
| 19 | len(string) | 返回字符串的长度或字符数 |
| 20 | ljust(width[, fillchar]) | 返回一个带有空格填充的字符串,其中原始字符串左对齐。 |
| 21 | lower() | 将字符串中的所有大写字母转换为小写。 |
| 22 | lstrip() | 移除字符串中的所有前导空格。 |
| 23 | maketrans() | 返回一个用于translate函数的翻译表。 |
| 24 | max(str) | 返回字符串str中的最大字母字符。 |
| 25 | min(str) | 返回字符串str中的最小字母字符。 |
| 26 | replace(old, new [, max]) | 将字符串中的所有old替换为new,或者如果max给出,则最多替换max个。 |
| 27 | rfind(str, beg,end) | 与find()相同,但反向搜索字符串。 |
| 28 | rindex( str, beg, end) | 与index()相同,但反向搜索字符串。 |
| 29 | rjust(width,[, fillchar]) | 返回一个带有空格填充的字符串,其中原始字符串右对齐。 |
| 30 | rstrip() | 移除字符串中的所有尾随空格。 |
| 31 | split(str num) | 将字符串按传递的参数分割,并返回尽可能多的列表。 |
| 32 | splitlines( num=string.count('\n')) | 在所有(或num个)换行符处分割字符串,并返回每个行的列表,删除换行符。 |
| 33 | startswith(str, beg,end) | 如果字符串或子字符串以str开头(如果提供了beg和end),则返回True。 |
| 34 | strip([chars]) | 对字符串执行lstrip()和rstrip()。 |
| 35 | swapcase() | 反转字符串中所有字母的大小写。 |
| 36 | title() | 返回字符串的“首字母大写”格式,意味着所有单词都以大写字母开头,其余的为小写字母。 |
| 37 | translate(table, deletechars="") | 根据翻译表str(256个字符)翻译字符串,删除del字符串中的字符。 |
| 38 | upper() | 将字符串中的所有小写字母转换为大写。 |
| 39 | zfill (width) | 返回原始字符串左填充零,总共为width个字符;适用于数字,zfill()保留任何符号(少一个零)。 |
| 40 | isdecimal() | 仅当Unicode字符串包含十进制字符时才返回True;否则返回False。 |
下面给出了最常用方法的示例,如lower()、upper()、join()、Split()、format()、replace()等。
S = 'Python world'
print(S.lower())
python world
S = 'Python world'
print(S.upper())
PYTHON WORLD
S = 'Python world'
print(S.replace('world','program'))
Python program

