

在本教程中,您将学习什么是正则表达式,它在编程中有多大用处,以及如何通过一些简单的示例和图表来实现模式匹配。此外,您还将学习导入're'模块,该模块包含一些有用的函数,如match、search、findall等。
在讨论正则表达式之前,让我们考虑一下我们在日常生活中有意或无意使用的特定功能,即使用“查找”搜索字符串,使用“查找和替换”在文字处理器和文本编辑器中查找和替换字符串,以及验证电子邮件和密码等输入。这些是如何发生的?答案就在本教程中。
什么是正则表达式?
正则表达式是定义某种搜索模式的字符序列。在编程环境中,正则表达式起着至关重要的作用,因为它为字符序列定义了搜索模式。正则表达式的缩写是Regex。
例如,
a*b = {b,ab, aab,aaab,aaaab,.......}
ab* = { a,ab, abb, abbb, abbbb,.....}
这里,a*b和ab*是语言{a,b}的正则表达式,*表示零次或多次。
现在,让我们开始学习Python中正则表达式的实现,从哪里开始,以及如何开始。在Python中,用于正则表达式的函数和方法都包含在一个名为re的模块中。因此,要执行任何Regex功能,必须导入re模块。下面显示了导入re模块的原型。
import re
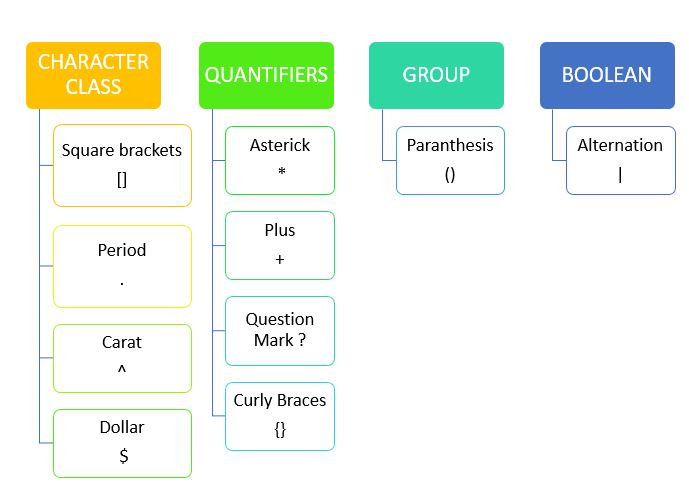
特殊字符(称为元字符)的运用增强了正则表达式的功能。在正则表达式中,元字符是对计算机程序具有特殊含义的字符。方括号([])、插入符号(^)、美元符号($)、句点(.)、竖线(|)、星号(*)、加号(+)、问号(?)、花括号({})、括号(())、反斜杠(\)等都是Regex中使用的一些元字符。
根据操作,元字符可分为以下几类:
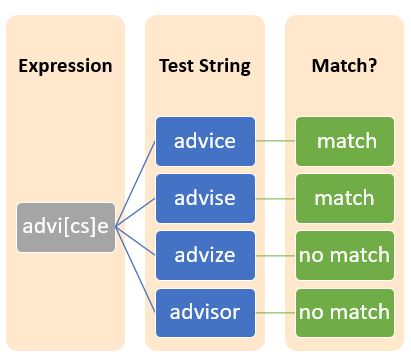
方括号是正则表达式中的一个元字符,用于定义字符集。换句话说,方括号内的字符构成字符集,并尝试匹配方括号内的任何单个字符。
示例
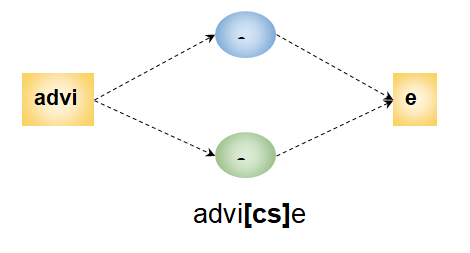
为了更好地理解,正则表达式可以可视化为:
使用方括号[],我们还可以表示字符范围。“-”(连字符)用于表示字符范围。例如:
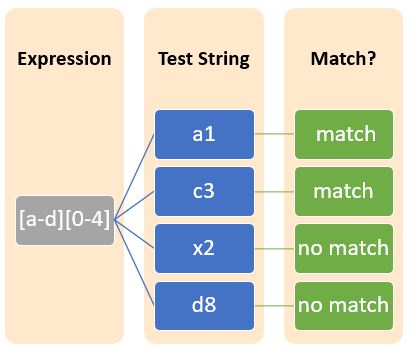
在此示例中:
[a-d]是与[abcd]等效的正则表达式。
[0-4]也是与[01234]等效的正则表达式。
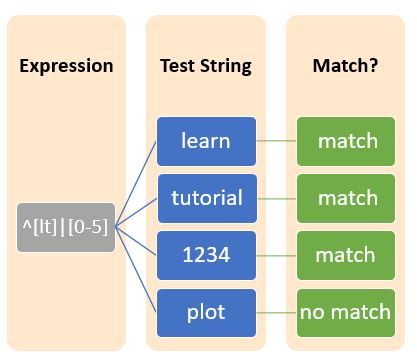
还可以反转字符集范围。这可以通过将插入符号(^)紧跟在方括号的开括号后面来完成。这可以视为:
句点或圆点充当通配符,匹配除换行符外的任何单个字符。句点的数量表示可以包含的字符数量。
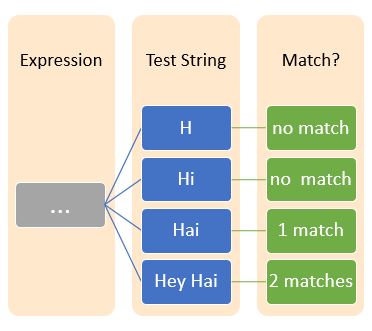
元字符^(插入符号)通常前缀一个字符,表示正则表达式以该特定字符开头。
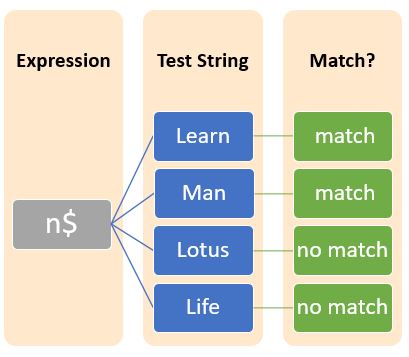
元字符$(美元符号)通常后缀一个字符,表示正则表达式以该特定字符结尾。
正则表达式中的量词表示字符、元字符或字符集的出现次数。*,+,?和{}属于量词。
星号(*)表示字符串中模式的零次或多次出现。

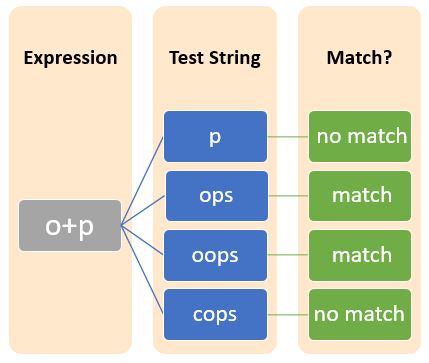
加号(+)表示字符串中模式的一次或多次出现。
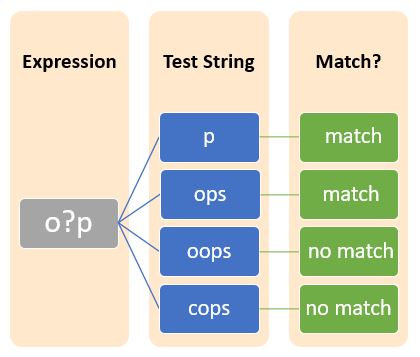
问号(?)表示字符串中模式的零次或一次出现。
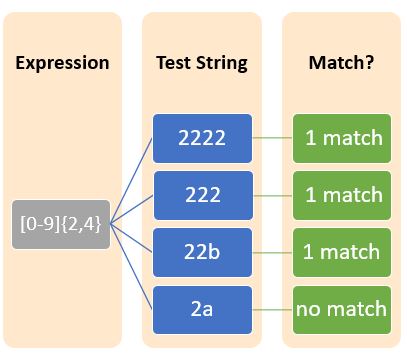
花括号也属于量词类别,用于表示某些字符、元字符或字符集的重复。花括号可以采取以下形式:
| {n} | 前面的字符精确地重复n次。 |
| {n,} | 前面的字符至少重复n次。 |
| { ,m} | 前面的字符最多重复m次。 |
| {n,m} | 前面的字符重复n到m次(包括n和m)。 |
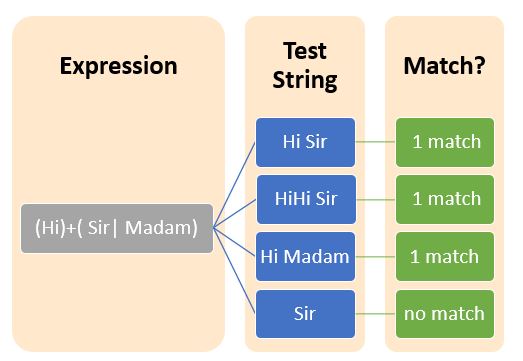
交替通常用于通过表示“此或彼”来实现逻辑OR操作。这可以通过竖线符号(|)来实现,它匹配一个正则表达式与任何可能的正则表达式。
形式为<regex-1>|<regex-2>|....|<regex-n>的正则表达式最多匹配<regex-i>中的一个。
分组结构将正则表达式分割成小的子表达式组。分组可以通过括号(())符号来完成。
| Regex | 解释 | 示例/匹配 |
|---|---|---|
| (Hi)+ | +应用于整个字符集 | Hi HiHi HiHiHi |
| Hi+ | +仅应用于字符“i” | Hi Hii Hiiii |
| Regex | 解释 | 示例/匹配 |
|---|---|---|
| This is a car|bus | |应用于'This is a car'和'bus' | This is a car bus |
| This is a (car|bus) | |应用于'This is a car'和'This is a bus' | This is a car This is a bus |
借助分组结构,我们还可以提取匹配子表达式或子模式的字符串片段。与组结构相关的捕获字符串的两种方法是group()和groups(),您将在本教程后面学习。
正则表达式中的反斜杠(\)用于转义特殊字符,包括元字符。通过在元字符前放置反斜杠,可以移除元字符的特殊含义,并将其指定为字面字符本身。例如,可以通过在其前面放置(\)字符来将元字符(?)问号视为字面字符。
此外,当您不确定某些字符的含义时,反斜杠也很有用,可以通过在字符前放置反斜杠来验证。
在正则表达式中,特殊序列是前缀为反斜杠的字符序列。下面列出了特殊序列及其含义和示例,以便于理解:

现在您已经很好地了解了正则表达式中使用的元字符和特殊字符。本节将教您如何使用一些常见且常用的正则表达式函数来实现它们。下面列出了与re模块相关的流行函数。
下面将对每个函数进行详细解释,并附有简单易懂的示例。
检查下面使用match()函数验证电子邮件格式的代码。
import re
string = '[email protected]'
pattern = '^[a-zA-Z0-9+_.-]+@[a-zA-Z0-9.-]+$'
result = re.match(pattern, string)
if result:
print("Valid email format")
else:
print("Invalid email format")
输出
Valid email format
在此示例中,我们使用match函数检查模式是否与提供的字符串匹配。在这里,我们使用正则表达式验证电子邮件格式,如果测试字符串不符合模式,则会输出“无效的电子邮件格式”。
re模块用于操作正则表达式的另一个方法是search()方法,它接受两个参数——模式和字符串。顾名思义,此方法搜索模式与字符串匹配的初始位置。如果找到完美匹配,则re.search()将返回一个匹配对象,否则将产生None作为结果。以下是示例:
import re
string = 'Python is a universal programming language developed by a Dutch Programmer called Guido Van Rossum in 1989 and released in 1991'
pattern ='\d'
result = re.search(pattern, string)
if result:
print("search successful")
else:
print("search unsuccessful")
输出
search successful
在这里,结果包含一个匹配对象。
此方法沿从左到右方向扫描字符串,并按找到的顺序返回所有匹配项的列表。
import re
string = 'Python is a universal programming language developed by a Dutch Programmer called Guido Van Rossum in 1989 and released in 1991'
pattern ='(\d+)'
result = re.findall(pattern, string)
if result:
print(result)
else:
print("search unsuccessful")
输出
['1989', '1991']
如果未找到匹配项,则结果将是一个空列表。
此方法与我们之前学到的方法略有不同。在此方法中,字符串将根据模式匹配进行分割,结果将是一个包含分割发生处的字符串列表。观察以下示例:
string = 'Python is a universal programming language developed by a Dutch Programmer called Guido Van Rossum in 1989 and released in 1991.'
pattern = '\d+'
result = re.split(pattern, string)
print(result)
输出
['Python is a universal programming language developed by a Dutch Programmer called Guido Van Rossum in ', ' and released in ', '.']
在上面的代码片段中,字符串在遇到数字时会进行分割。当找不到匹配项时,split()方法将返回一个包含原始字符串的列表。split方法的另一个特点是可以通过为参数maxsplit指定一个值来限制分割次数。
import re
string = 'Python is a universal programming language developed by a Dutch Programmer called Guido Van Rossum in 1989 and released in 1991.'
pattern = '\d+'
result = re.split(pattern, string,1)
print(result)
输出
['Python is a universal programming language developed by a Dutch Programmer called Guido Van Rossum in ', ' and released in 1991.']
注意:默认情况下,maxsplit的值为零(所有可能的分割)。
此方法将匹配项替换为所需的字符串。
import re
string = 'abc 123 def 456 ghi 789'
pattern = '[a-z]'
replace = '0'
result = re.sub(pattern,replace,string)
print(result)
输出
000 123 000 456 000 789
与split()一样,您可以通过将可选参数count设置为一个值来限制替换次数。默认情况下,count的值为零,这意味着将执行所有可能的替换。
import re
string = 'abc 123 def 456 ghi 789'
pattern = '[a-z]'
replace = '0'
result = re.sub(pattern,replace,string,4)
print(result)
输出
000 123 0ef 456 ghi 789
在上述方法中,您已经看到了一个可选参数flags,它是用于控制匹配各个方面的修饰符。默认情况下,flags的值为零。
正则表达式中的匹配对象是包含搜索和结果信息的对象。匹配对象始终包含真值(True或False)。如果没有匹配项,则返回None而不是匹配对象。观察以下代码的输出:
import re
string = 'I am 18 years old.'
pattern = '\d+'
result = re.search(pattern, string)
print(result)
输出
span=(5, 7), match='18'
匹配对象具有以下属性和方法来获取搜索和结果的信息:
span():返回一个包含匹配项的开始和结束索引的元组。
group():返回与模式匹配的字符串部分。
String:返回传入的字符串。
import re
string = 'I am 18 years old.'
pattern = '\d+'
result = re.search(pattern, string)
print(result.span())
print(result.group())
print(result.string)
输出
(5, 7) 18 I am 18 years old.
要了解有关匹配对象属性和方法的更多信息,请访问Python的文档页面。

