

环顾四周,你就会明白数据无处不在。
例如,人类只能存储有限的信息量。如今,技术日新月异,因此,在手机上轻轻一点,就会产生比我们所知道的更多的数据。
因此,数据将指为分析或参考而收集的事实和统计数据。
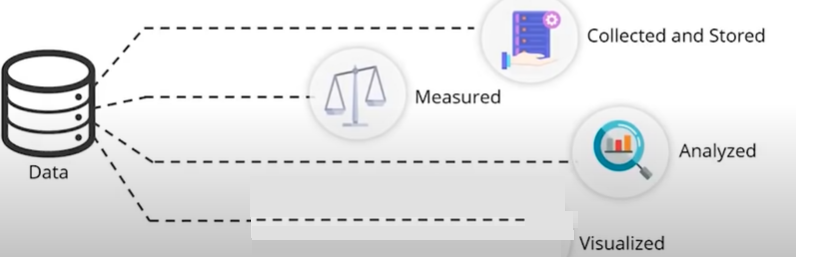
数据可以从不同的来源生成。
这些生成的数据是:
这些步骤是使用统计模型和图表完成的。
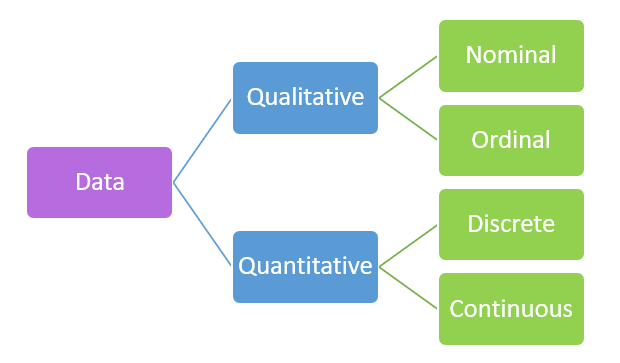
数据主要分为两类:
定性数据主要处理不易测量但可以主观观察的特征和描述符。
定性数据进一步分为名义数据和序数数据。
名义数据是任何没有顺序或排名的类型数据。
名义数据的两个例子:
1. 性别
2. 种族
1. 性别
名义数据的一个例子是性别。如果我们以性别为例,很明显它没有排名。只有男性和女性两个类别,没有像1、2这样的排序。
2. 种族
种族是名义数据的另一个例子,它没有任何顺序或排名。
它是有序的信息系列。如果数据是有序的,则此类数据称为序数数据。
序数数据的一个例子:
拉朱是一位商人,有一天他去了一家酒店,他的所有信息都以客户ID的形式存储。这意味着他用客户ID表示。在他离开酒店之前,他想对他们的服务进行评分。他可以将他们的服务评为良好或一般。像拉朱一样,酒店管理部门将记录其他入住过酒店的客户及其评分。
如果任何数据具有某种顺序,则此类数据称为序数数据。
定量数据有两种类型:
1. 离散数据
2. 连续数据
离散数据也称为分类数据。这是一种可以保存有限数量可能值的数据。
离散数据的例子:
音乐课上的学生人数是离散数据的一个例子,因为音乐课上的学生人数是有限的。
连续数据是一种可以包含无限数量可能值的数据。
连续数据的例子:
一个人的体重是连续数据的最佳例子。假设希塔的体重是54公斤,或者54.1公斤,或者可以是54.001公斤,这表明有无限数量的可能值。这种数据被称为连续数据。
离散变量也称为分类变量,这意味着它可以保存不同类别的值。
例如:假设你有一个名为“MESSAGE”的变量,这个变量{message}主要可以保存两种类型的值。这意味着消息可以是垃圾邮件或非垃圾邮件。所以这里的变量MESSAGE被称为分类变量,因为它代表了不同类别的数据。
它可以存储无限数量的值。
例如,一个人的体重可以表示为一个连续变量。假设有一个名为“WEIGHT”的变量,它可以存储无限数量的可能值,因此变量WEIGHT被称为连续变量。
它是一个应用数学领域,涉及数据的收集、分析、解释和呈现。
统计方法用于可视化数据、收集数据和解释数据。
数学领域主要有助于理解如何使用数据来解决非常复杂的问题。
可以使用统计学解决的一些问题示例。
示例 1
Xyz 是一家非常著名的公司,上个月他们发明了一种可能治愈肺结核的新药。
我们如何检查药物的有效性?
解决方案:这可以通过统计学来解决。
第一步是创建一个测试,以帮助了解所发明药物的有效性。
示例 2
拉胡尔和雷玛是最好的朋友。两人都在看足球。突然,拉胡尔向雷玛打赌,关于哪支球队将赢得比赛,是蓝色队还是红色队。
这是另一个属于统计学的问题。这个问题可以通过统计学来解决。
数据科学家主要使用统计学来:

