

在本教程中,我们将讨论数据科学的整个生命周期。它主要涉及如何执行数据或分配的项目。
数据科学生命周期是一种框架,它提供了一些关于如何开发数据科学项目的信息或步骤。它主要包含数据科学家在项目开始时应遵循的一些步骤,并持续到项目结束。这些步骤并非固定不变,可以跳过或重复,直到我们获得正确或满意的结果。根据项目的不同,有时可能需要几个月才能完成,因为这是一个漫长的过程。
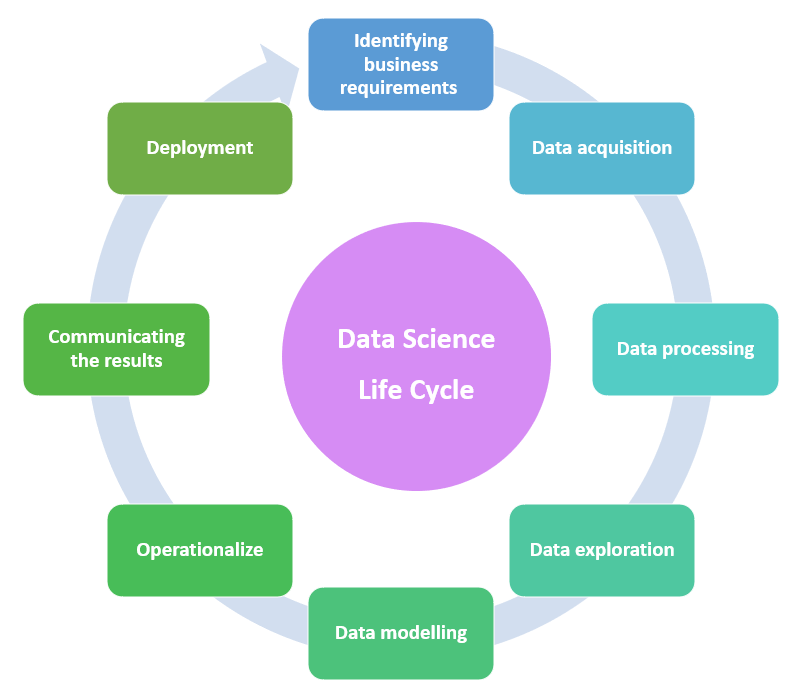
这是数据科学生命周期的第一步。收集所有来自可用数据源的信息,识别问题并找出目标是此步骤中完成的两项主要工作。
在开始项目之前,我们首先应该清楚地了解项目需求、客户需求和市场趋势。所有这些都应清楚地识别,以获得更好的结果。
如何识别业务需求?
从多个来源收集数据意味着,数据科学家从不同的来源(如数据库、API、网页、在线存储库等)收集信息。应从可用来源收集所需信息。为了从特定来源读取数据,可以使用一些特殊的包,如R或Python。许多宝贵的数据也从YouTube、Twitter、Facebook等社交媒体收集。
从文件中收集数据被称为传统的数据收集方式。收集信息的5种主要方法是通过进行调查和问卷调查,第二种方法是通过进行访谈,直接向受访者提问来收集数据,第三种是小组讨论中收集数据,第四种是直接观察,最后一种是从文件中收集信息。这些是收集信息的5种主要方法。
在此步骤中完成数据清洗和数据转换。
获取的数据不会是干净的,因此在进入下一步之前需要对数据进行处理,这意味着从不同来源获取的原始数据应进行清洗。原始数据的清洗通过擦洗和过滤完成。在清洗数据时,如果发现任何缺失的数据集,应进行适当的替换。这意味着在清洗原始数据时,也进行替换和撤回值。
从已清洗的数据中理解不同的模式,并从中提取有用的见解。在使用数据之前应对其进行检查。之所以这样做,是因为数据可能包含不同类型的数据,如数值数据、序数数据、名义数据以及分类数据。不同类型的数据应以不同的方式处理,因此只有对数据进行适当的检查才能帮助识别不同类型的数据。
为了理解不同的模式,数据科学家可以使用直方图、Microsoft Excel电子表格等。
在数据建模中,创建一个模型,该模型最准确地预测目标,并对所创建的模型进行评估和测试,以检查其效率。模型规划中使用的各种工具包括R、Python、MATLAB和SAS。
数据模型主要有两种类型:概念数据模型和物理数据模型。数据库的概念及其之间的现有关系在概念数据模型中以可视化方式表示,此模型包含实体/子类型、属性、关系和完整性规则。在概念数据建模之后,下一步是物理数据模型。这意味着每个数据实体的属性在此处清晰定义。物理数据模型由表、列、键和触发器组成。数据建模包含许多图表、符号或文本,这些主要用于根据数据如何相互关联来表示数据。
在此阶段,将检查上一步中选择的模型,这意味着它将运行该模型以了解其工作原理。在运行模型后,将记录基于其性能的发现,并提交最终报告。最终报告包含所有必要的简报、代码详细信息、性能详细信息和技术信息。如果他们的发现是完美的,那么它就可以使用了,团队还将在此时提交最终报告、代码以及技术文档。
在此阶段,项目结果和有价值的发现可以传达给负责人员。在这里,他们可以将其与我们最初识别问题时的发现进行比较,以检查数据是否提供了有用的见解。
讨论后,如果结果质量需要改进或发现任何错误,那么我们必须再次从第一步开始。如果未发现错误且上级对数据科学家及其团队的工作感到满意,那么我们可以进入最后一步。
部署是数据生命周期的最后一步。此阶段的主要目标是将模型部署到生产环境中。用户对模型的性能进行验证。模型的性能受到非常仔细的监控,如果需要任何更改,也在此阶段进行。将进行持续监控,因为数据趋势日々变化,因此我们应根据情况对模型进行一些更改,主要是为了适应新的发展趋势并避免性能退化。

