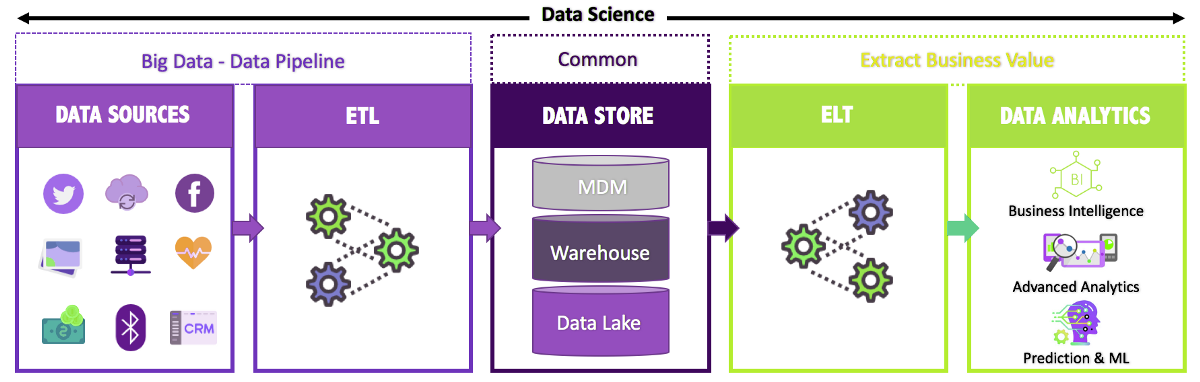
在本模块中,我们将讨论数据科学与大数据之间的主要区别和相似之处。我们还将讨论成为成功的数据科学家、数据分析师和大数据专业人士所需的角色和职责以及最重要的技能。
数据科学是一种通过使用机器学习、统计学、数学、编程等各种概念来理解和实现每个公司的业务需求的方法。通过所有这些概念,从不同来源收集的数据中提取有用的见解和模式。
主要是利用人工智能和机器学习,数据科学家将从收集到的数据中找出隐藏的模式和有用的见解,并将其用于业务发展。
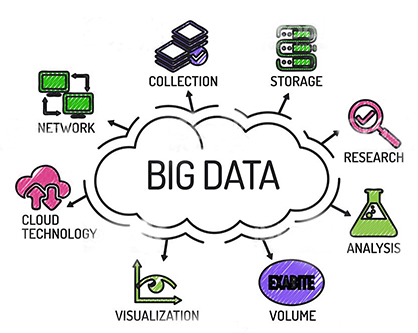
它始终指每秒从不同来源生成的大量数据,获得的数据将以各种格式存在,例如视频文件、音频文件、文本文件、jpeg文件以及许多其他不同格式的数据。
我们有用于处理数据的传统系统,但传统系统的问题在于它们无法处理所有以不同格式生成的海量数据。海量数据意味着数据量巨大,并且数据会随时间快速增长,这类数据被称为大数据。如果数据集非常庞大,并且无法使用传统处理系统进行处理,那么这类数据就是大数据。大数据的一些例子包括主要用于自动驾驶汽车的实时道路测绘、媒体流、个人营销等等。
大数据可以分为三类:结构化数据、非结构化数据、半结构化数据。
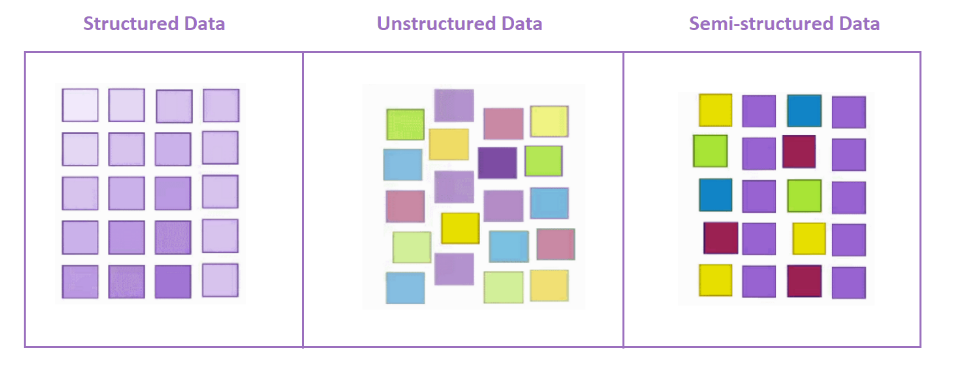
如果收集到的数据可以被访问、处理和存储在特定的固定格式中,那么这类数据就是结构化数据。这意味着如果数据以标准化格式并经过适当分类提供,则为结构化数据。
结构化数据示例
数据库中的“学生”表可视为结构化数据的例子。
| 学生ID | 学生姓名 | 性别 | 部门 | 分数 |
|---|---|---|---|---|
| 1234 | 约翰·弗朗西斯 | 女 | 计算机科学与工程 | 92 |
| 4567 | 詹姆斯 | 男 | 机械工程 | 98 |
| 9876 | 约翰·多伊 | 男 | 土木工程 | 88 |
| 1357 | 詹妮弗 | 女 | 计算机科学与工程 | 78 |
| 3542 | 伊芙琳 | 男 | 电子与通信工程 | 90 |
这是另一种大数据,其中信息或数据未按特定模式排列。非结构化数据的最佳示例是音频文件、视频文件、日志文件、图像文件等等。
示例: “谷歌搜索”返回的输出
这类数据总是包含结构化数据和非结构化数据的两种格式。半结构化数据是有组织的,但不如结构化数据组织得好。
示例:标记语言、XML 和压缩文件等。
| 数据科学 | 大数据 |
|---|---|
| 它始终与数据分析打交道。 | 处理大量数据 |
| 通过理解数据中的模式做出决策 | 在这里,处理海量数据并提取见解 |
| 工具:SAS、R、Python | 工具:Hadoop、Spark、Flink |
| 应用领域:互联网研究、图像和语音识别、数字广告等。 | 应用领域:医疗保健、旅游业、游戏等。 |
| 数据科学家 | 大数据专业人员 |
|---|---|
| 对机器学习和编程有深入了解 | 创造力 |
| 分析和统计技能 | 商业技能 |
| 深度学习 | 数据可视化 |
| 数学技能 | MATLAB 知识 |
| SAS/R 编码 | 基础编程 |
| 沟通技巧 | SQL 编码 |
| 团队合作能力 | 处理非结构化数据 |
数据科学与大数据之间的主要区别如下:
数据科学家主要构建模型,目的是从数据中获取洞察和隐藏模式,这也有助于对公司的未来业务做出预测。大数据工程师则负责构建数据、测试以及维护数据管道。经验丰富的大数据工程师的起薪约为每年866,234卢比。具有1到4年最低经验的初级大数据工程师的年薪约为566,234卢比。
数据科学家将始终训练预测类型的数据模型,以及从大数据工程师那里接收到的数据。大数据工程师将找出有助于数据科学家访问和分析数据的解决方案。
如果有人一直想成为数据科学家,他会认为数据科学家比大数据工程师更好,反之亦然。数据解释只能由数据科学家在数据以适当格式接收时进行。大数据工程师的主要作用是向数据科学家提供数据,以便从数据中提取有用的见解。
大数据是数据科学的一部分。