

数据框是开始学习 R 编程语言最重要也是最广泛使用的原因之一。R 是一种统计编程语言,它处理数据集。这些数据集由观察或实例组成。所有观察都与它们的一些变量相关联。
考虑一个包含 6 名学生的数据集,其中每位学生是一个实例,与这些学生相关的属性,如他们的学号、姓名、成绩和他们所属的班级,是变量。
那么,如何存储这些信息呢?
我们可以使用 矩阵 吗?不,因为矩阵只包含相同数据类型的元素或数据。
这里,学号是数值型的,姓名是字符型的,成绩可以是字符型,这不适合矩阵,但可能适合 列表。列表可以将这些信息作为子列表存储,包含学号、姓名等……但列表的结构并不太适合使用。另一个限制是,要获取任何列都需要编写一些 R 代码。
那么,哪种数据结构可以克服这种情况呢?这就是 R 编程语言中重要且广泛使用的数据框概念的由来。
在 R 编程语言中,数据框是一种基本的数据结构,允许在表中存储典型数据。因此,数据框就像一个带有行和列的电子表格。在数据框中,行对应于观察,列对应于变量。每一列都可以是不同的向量。
frame 这个词代表结构、形状、设计或模式。因此,data frame 这个词的含义可以推断为一种勾画数据信息或简单地以一种明确的框架组织数据的结构/形状/设计/模式。
考虑一个电子表格或表格,其中包含一些学校学生的信息,包括他们的学号、姓名和考试成绩。该列指定了每个学生的属性。
这里,行 = 观察(学生),列 = 变量(学号、姓名、成绩)
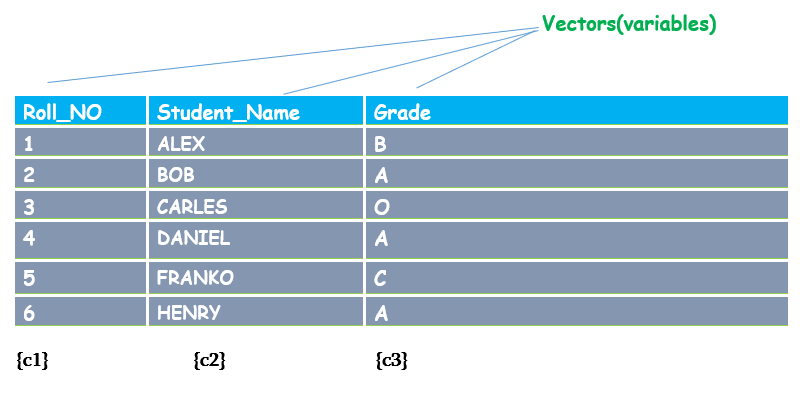
同一张表格可以用 R 程序中称为“数据框”的数据结构来表示。数据框的每一列可以是不同的 向量,如数值型、字符型等。在给定的 student_table 中,第一列(c1)由数值型数据类型向量组成,第二列(c2)和第三列(c3)由字符型数据类型组成。
数据框类似于列表数据结构。一个 列表 由一系列以列表格式列出的异构数据元素或组件组成,所有向量的长度都相等。数据框类似于列表的特殊情况,除了数据以框架形式显示。就像列表中一样,数据框的向量组件长度也相等。
由于有行和列,它也似乎类似于 矩阵。数据框与矩阵之间的一个很大区别是,数据框可以包含不同类型的元素:一列可以是字符,另一列可以是数值或逻辑型,这取决于要求。
然而,在数据框中,仍然存在一个限制。同一列的所有元素的数据类型应相同。
例如,从上表可以识别出具有学号变量的列,其中所有元素都是数值数据类型。
让我们直观地比较一下列表和数据框的区别。以便更好地理解 R 中数据框的概念。

与列表中的相同数据在数据框中以表格形式显示。
现在,让我们通过学习创建数据框来开始讨论 R 编程语言的实际部分。
在 R 编程语言中,您无需自己创建数据框,而是可以从其他来源导入数据。其他来源可以是 CSV 文件、关系数据库(例如 SQL)或来自其他软件程序,如 EXCEL、SPSS 等。
R 也提供了手动创建数据框的方法。在 R 中,使用内置函数 data.frame() 创建数据框。要为 6 个观察值(行)和 3 个变量(列)创建数据框,您需要将 3 个相同长度为 6 的向量传递给 data.frame() 函数。
data.frame()
括号 () 包含任何指定数据类型的向量作为参数。向量(如 vector1、vector2 等)在 data.frame() 函数外部创建,并将这些向量名称作为参数传递到函数括号中。
<variable_name> = data.frame(<vector1><vector2><…………>)
让我们学习如何为前面提到的 student_table 创建数据框。
该表包含三列(c1、c2、c3)。列 c1 是表中的学生学号。为 c1 中的学号创建向量。我们知道向量是使用 c() 函数创建的。
列 c2 是 Student_Name,它是字符类型,如 ALEX、BOB 等;c3 是学生的 Grade,也是字符类型,如 B、A 等。每一列代表向量(变量),行代表观察。您可以推断每列和行值之间的一些有效关系。
Roll_No = c(1,2,3,4,5,6)
Student_Name = c("ALEX","BOB","CARLES","DANIEL","FRANKO","HENRY")
Grade = c("B","A","O","A","C","A")
D = data.frame(Roll_No, Student_Name,Grade )
创建了一个包含 向量 Roll_No、Student_Name、Grade 的数据框,并将其分配给一个 变量 D。
创建数据框需要遵循的步骤是
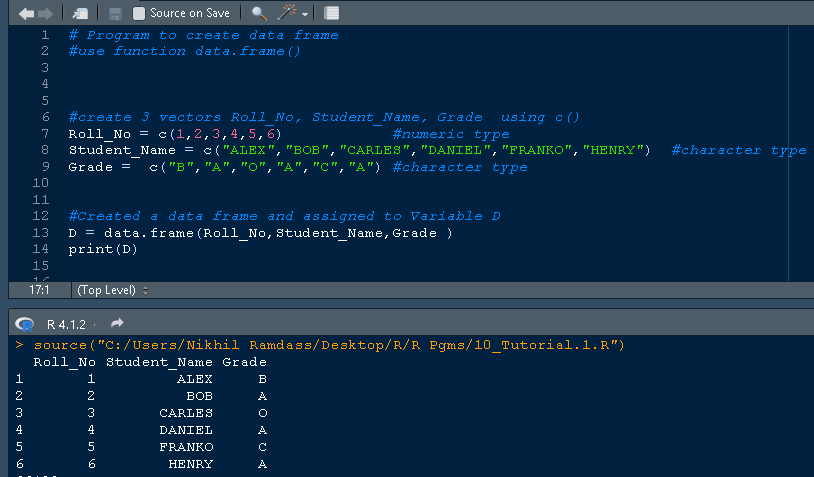
为 student_table 创建数据框的完整源代码如下。
#create 3 vectors Roll_No, Student_Name, Grade using c()
Roll_No = c(1,2,3,4,5,6) #numeric type
Student_Name = c("ALEX","BOB","CARLES","DANIEL","FRANKO","HENRY") #character type
Grade = c("B","A","O","A","C","A") #character type
#Created a data frame and assigned to Variable D
D = data.frame(Roll_No,Student_Name,Grade )
print(D)
输出
Roll_No Student_Name Grade 1 1 ALEX B 2 2 BOB A 3 3 CARLES C 4 4 DANIEL A 5 5 FRANKO C 6 6 HENRY A
RStudio 中相同代码的片段是
注意:三个向量 Roll_No、Student_Name、Grade 的长度相同。
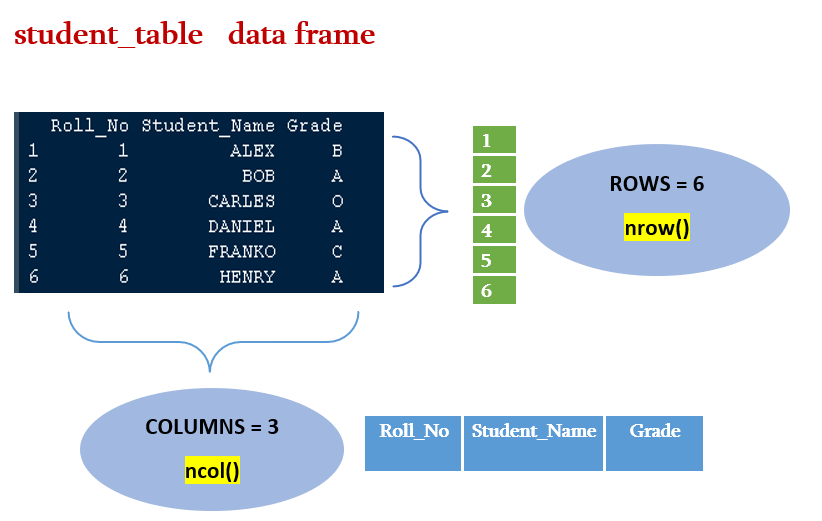
可以使用以下语法计算数据框中的行数和列数
nrow()
括号中包含已分配数据框的变量名。在我们之前的示例中,我们将 student_table 的数据框存储在变量 D 中。让我们检查 student_table 中的行数,
> nrow(D)
[1] 6
nrow(D) 返回值为 6,表示表中共有 6 行。
ncol()
要计算数据框内的列数,请使用 ncol(),括号中包含需要检查列数的数据框名称。
让我们检查我们的 student_table 中的列数,
> ncol(D)
[1] 3
您可以看到数字 3,ncol() 函数返回值为 3,表明我们的数据框 D 中有 3 列。
可以使用单个函数计算行数和列数。
dim()
让我们检查 student_table 的行数和列数输出,
> dim(D)
[1] 6 3
该函数返回行数(6),然后是列数(3)。
R 编程语言具有内置函数 names(),该函数支持设置和获取 R 数据框组件的名称,例如列名。names() 函数是一个通用函数,用于访问 R 对象的名称属性。
在我们的 向量 和 矩阵 教程中,我们讨论了 names() 函数,其中我们为向量和矩阵数据结构分配了值作为名称。
这里,names() 函数通过在方括号 [ ] 中提及列号来获取与列号对应的名称。names() 函数包含您创建的数据框名称,您需要从中访问名称。
names()[]
在我们之前的会话中,我们创建了一个具有三个向量的数据框 D,这些向量在数据框中形成列,向量的值作为行。
考虑 student_table,names(D) 函数检查名为 D 的数据框,然后通过 [] 中的列号 1 进行评估。该函数将 [1] 评估为数据框 D 中的第一列,并返回 Roll_No 名称。
> names(D)[1]
[1] "Roll_No"
names()[] 获取数据框中的列名
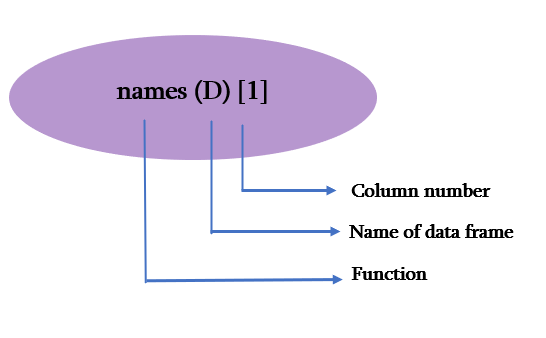
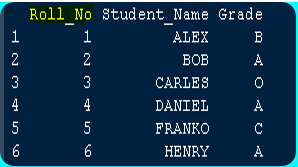
检索到的列名是 Roll_No。您可以从图像中观察输出以更好地了解 names()。
head() 和 tail() 函数是 R 编程语言中的内置函数,可帮助用户根据自己的偏好查看输出数据。在某些情况下,如果大量数据集或数据库被导入到您的 R 程序中,它可能包含许多列和行。在我们 student_table 的示例中,只有 3 列和 6 行,很容易观察并得出我们的推论。
但对于大型数据库则不然,因此用户可以使用 head() 函数查看初始数据集(顶部),使用 tail() 函数查看最终数据集(底部)。
head(<name of data frame>)
head(<name of data frame>)
数据框的结构可以通过使用一个名为 str() 的函数来找到。
str(<name of data frame>)
让我们使用 str() 函数检查我们上面创建的 student_table,即 D 数据框的结构
str(D)
str() 函数确定数据框 D 的结构,并返回以下观察结果:
这是一个具有三个变量的 6 个观察值的数据框结构。这三个变量是 Roll_No、Student_Name 和 Grade。此外,它还提供了详细信息,例如变量 Roll_No 是数值数据类型(num),具有以下观察值,如 1、2、3、4、5、6。
变量或向量 Student_Name 是字符数据类型(chr),具有以下观察值,如“ALEX”、“BOB”、“CARLES”、“DANIEL”……
最后一个是 Grade,一个字符类型(chr)的向量,观察值为“B”、“A”、“O”、“A”……
输出
'data.frame': 6 obs. of 3 variables: $ Roll_No : num 1 2 3 4 5 6 $ Student_Name: chr "ALEX" "BOB" "CARLES" "DANIEL" ... $ Grade : chr "B" "A" "O" "A" ... >
R 数据框的摘要使用 R 中的内置函数 summary() 来查找。
summary(<name of data frame>)
函数名 summary 后跟括号中的数据框名称()。请记住我们使用 data.frame() 函数创建的数据框 D
#create 3 vectors Roll_No, Student_Name, Grade using c()
Roll_No = c(1,2,3,4,5,6) #numeric type
Student_Name = c("ALEX","BOB","CARLES","DANIEL","FRANKO","HENRY") #character type
Grade = c("B","A","O","A","C","A") #character type
#Created a data frame and assigned to Variable D
D = data.frame(Roll_No,Student_Name,Grade )
print(D)
生成的输出是如下面的片段所示的表格格式
现在,让我们使用 R 提供的 summary() 函数检查同一数据框 D 的摘要。
summary(D)
其中 summary 是函数名,D 是我们创建的数据框名。让我们看看上述语法产生的输出
输出
> summary(D)
Roll_No Student_Name Grade
Min. :1.00 Length:6 Length:6
1st Qu.:2.25 Class :character Class :character
Median :3.50 Mode :character Mode :character
Mean :3.50
3rd Qu.:4.75
Max. :6.00
RStudio 中的相同结果由片段显示,以便更好地理解 D 数据框的摘要。
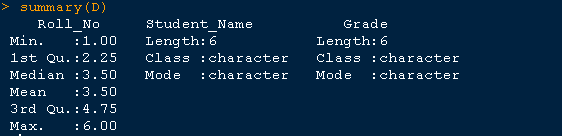
摘要显示
同样,Student_Name 和 Grade 两个向量的摘要是
要在 R 数据框中添加列,请遵循下面的语法。
<name of existing data frame> <$><name of new vector> = c(<value1>,<value2>………)
让我们来看一下我们上面讨论的 D 数据框的语法
D$Section <- c("A","B","A","B","A","B")
Or Secti
D Secti
向数据框 D 添加了一个新向量 (section),section 是一个使用 c() 创建的值为“A”和“B”的向量。
让我们看看添加新列 section 到我们的数据框 D 后的输出。
输出
Roll_No Student_Name Grade Section
1 1 ALEX B A
2 2 BOB A B
3 3 CARLES O A
4 4 DANIEL A B
5 5 FRANKO C A
6 6 HENRY A B
相同代码的片段是
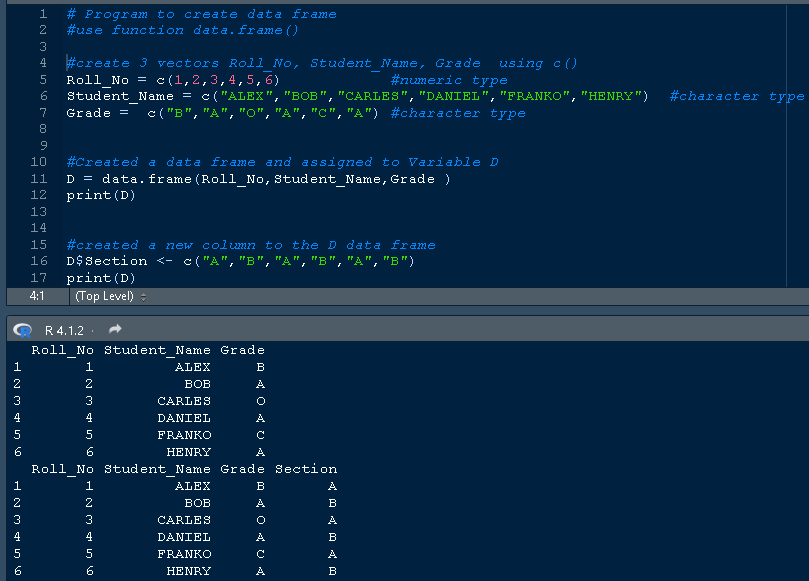
从片段中,您可以推断出新的列 section。初始数据集代表旧数据框 D,只有 3 列,紧接着下面,您可以查看包含附加列 section 的相同数据集。很明显,新数据框现在包含 4 列,如 Roll_No、Student_Name、Grade、Section。
要识别列数,请使用我们在同一教程的先前会话中学习过的 ncol() 函数。
让我们看一下新的 D 数据框中的列数
> ncol(D)
[1] 4
>
cbind() 函数也用于添加列。(参考 矩阵 教程回顾 cbind())
cbind(D,Section)
使用 cbind() 函数后,输出结果是将 Section 列添加进去,如下面的片段所示。

R 中包含两种子集化技术来子集化数据框。
考虑我们在上面的主题中创建的具有 4 列和 6 行的新数据框 D。
让我们先从数据框中选择单个元素。
假设您需要选择学号为 5 的学生姓名,该学生位于我们数据框的第五行。我们使用单个括号 [.来子集化。数据框名称(D)后跟单个括号 [ ,参数首先代表观察(行索引)号(5),然后是列号(2)。
让我们来看一个包含示例的语法
Data.frame_name[nrow,ncol]
D[5,2]
[1] "FRANKO"
我们通过指定数据框中的行号和列号来获取学生姓名“FRANKO”。将列名而不是列号给出也会产生相同的结果,如下所示。
> D[5,"Student_Name"]
[1] "FRANKO"
D[<nrow> , ] #to subset entire row
D[ , <ncol>] #to subset entire column
要检索或子集化“FRANKO”的所有信息,您可以使用以下代码
> D[5,]
Roll_No Student_Name Grade Section
5 5 FRANKO C A
结果是一个只有一行观察值的数据框。
现在,要获取 Student_Name,语法 D[ , <ncol>] 将起作用。
> D[,"Student_Name"]
[1] "ALEX" "BOB" "CARLES" "DANIEL" "FRANKO" "HENRY"
结果类似于向量,因为列包含相同数据类型的元素。
> D[c(2,5), c("Student_Name","Grade")]
Student_Name Grade
2 BOB A
5 FRANKO C
行号或观察值通过 c() 提供,列名接下来在 c() 中给出,以获取与行和列相对应的值。

