

在本节中,我们将讨论如何使用 R 包提供的不同类型的内置函数在 R 编程语言中操作字符串。
下表简要概述了函数名称及其相应的操作或性能。
| 字符串操作函数 | 描述 |
|---|---|
| paste() | 连接字符串。 |
| format() | 格式化数值。 |
| nchar() | 计算字符串中的字符数。 |
| substr() | 从字符串中提取特定字符 |
| grep() | 从字符串中提取特定模式。 |
| strsplit() | 分割字符字符串中的元素。 |
| tolower() | 将小写字符串转换为大写字符串 |
| toupper() | 将大写字符串转换为小写字符串 |
让我们详细了解每个函数。
R 中的 paste() 函数用于将两个或多个字符串组合在一起形成一个新字符串。换句话说,paste() 函数在将向量转换为字符后进行连接。
paste 函数将其中的参数转换为字符字符串并进行连接。如果参数是向量,它们将逐项连接以生成字符向量结果。向量参数会根据需要回收,零长度参数仅在 recycle0 不为真或 collapse 不为 NULL 时才回收为“ ”。
paste (..., sep = " ", collapse = NULL, recycle0 = FALSE)
paste0(..., collapse = NULL, recycle0 = FALSE)
其中,
如果为 collapse 指定了值,则结果中的值将连接成单个字符串,元素之间用 collapse 的值分隔。
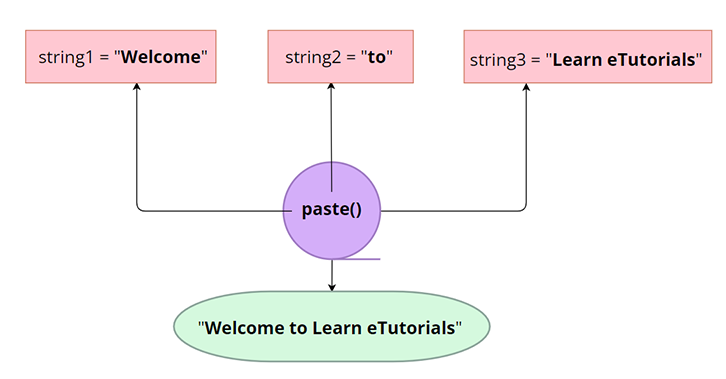
#use paste() function
string1 = "Welcome"
string2 = "to"
string3 = "Learn etutorials" c string2, string3)
print(concatStr)
输出
[1] "Welcome to Learn etutorials"
paste("Welcome", "to"," Learn etutorials ", sep = "----") #paste with separator
sep=”---” 是一个字符字符串,它分隔 paste() 函数中给定的 welcome、to、Learn etutorials 参数。
输出
[1] "Welcome----to---- Learn etutorials "
当分隔符更改为 sep=”___” 时,输入和输出变为
> paste("Welcome", "to"," Learn etutorials ", sep = "___") #paste with separator
[1] "Welcome___to___ Learn etutorials "
x <- c("example","of","paste","with","collapse")
print(x)
paste(x)
向量对象 x 包含几个不同的字符字符串。当 paste 函数应用于此向量对象 x 时,它返回与向量输出相同的结果。让我们看看输出以区分向量输出(print x)和 paste() 函数应用于向量 x(paste(x))时的结果。
> print(x)
[1] "example" "of" "paste" "with" "collapse"
> paste(x)
[1] "example" "of" "paste" "with" "collapse"
你可以观察到两个结果是相同的。向量对象 x 的字符字符串没有与 paste 函数合并。因此,为了合并向量对象的元素,你需要指定 collapse 参数。
paste(x,collapse = " ")
在 collapse 参数中,你需要指定另一个字符字符串作为分隔符。此处 collapse = " " 表示向量对象 x 元素将与一个空值合并。当代码运行时,输出是
paste(x,collapse = " ")
[1] "example of paste with collapse"
通过合并向量中的所有元素返回另一个字符字符串。
| paste() | paste0() | |
|---|---|---|
| 输入 | paste("Welcome", "to"," Learn etutorials ", sep = "") | paste0("Welcome", "to"," Learn etutorials ") |
| 输出 | [1] "Welcome to Learn etutorials " | [1] "Welcome to Learn etutorials " |
| 推论 | 需要指定分隔符,即 sep。 | 无需指定分隔符。默认使用空字符字符串作为分隔符。 |
推论:paste0() 函数是 R 编程语言中 paste() 函数的替代方案,它是一个更高效、更方便的字符串合并函数。从上表可以看出,paste() 和 paste0() 都提供相似的输出。
R 编程语言中的 nchar() 函数计算字符串中包括空格在内的字符数。此函数包含一个字符向量作为其参数,并返回一个向量,其元素由字符串中不同大小的元素组成。R 中的 nchar 函数是找出字符向量元素是否为非空字符串的最快、最有效的方法。
nchar(x, type = "chars", allowNA = FALSE, keepNA = NA)
nzchar(x, keepNA = FALSE)
其中参数
考虑一个包含单个字符对象或变量字符串 str0 的示例。要检查字符串 str0 包含多少个字符,我们对 str0 应用 nchar() 函数。该函数在 RStudio 控制台中返回一个相应的值。在我们的示例中,对 str0 应用 nchar() 返回 27 的值。每个字符都被计数,包括分隔给定单个字符串中两个单词的空格。
# use nchar() function
#Returns the count of number of characters including space present in it
str0 = "welcome to Learn eTutorials" #create a character object /string str0
print(nchar(str0)) #Apply nchar() in R
输出返回字符计数值。
输出
[1] 27
现在让我们考虑一个使用 向量 数据类型的示例。使用 c() 函数创建一个向量 str1,其中包含 4 个元素,分别是 "welcome"、"to"、"Learn"、"eTutorials"。对 str1 应用 nchar() 返回给定向量 str1 中每个不同单词或字符串中的字符数。例如,字符串“welcome”(向量中的一个单词/元素)在应用 nchar 函数后返回 7,其余元素也如此。
str1=c("welcome","to","Learn","eTutorials")
print(str1)
nchar(str1)
输出
> print(str1) [1] "welcome" "to" "Learn" "eTutorials" > nchar(str1) [1] 7 2 5 10
从输出中,你可以看到给定向量中每个字符字符串对应多少个字符。
为了处理给定输入中存在的 NA 值,nchar() 函数中提供了可选参数 keepNA。
vector0<- c(NA,"R", 'TUTORIAL', NULL)
nchar(vector0, keepNA = FALSE)
创建了一个名为 vector0 的向量,其中包含一些元素。让我们先看看向量输出是如何显示的。
print(vector0)
[1] NA "R" "TUTORIAL"
执行短代码后,上述字符串显示在 R 控制台中。现在让我们找出在应用 nchar() 并添加另一个可选参数“keepNA”后,相同代码会发生什么变化。
> nchar(vector0)
[1] NA 1 8
NA 值被排除在计算给定向量(即 vector0)中每个字符串的字符数之外。该函数计算其余字符串的字符并返回如图所示的值,例如“R”有 1 个字符,“TUTORIAL”有 8 个字符,依此类推。
当 keepNA 设置为 TRUE 时,keepNA=TRUE 会产生与上面相同的结果。
nchar(vector0, keepNA = TRUE)
[1] NA 1 8
NA 不会被计数,通过将值从 TRUE 更改为 FALSE,允许 nchar() 函数计算给定输入中是否存在 NA 并返回其相应的值。
> nchar(vector0, keepNA = FALSE)
[1] 2 1 8
nchar() 和 nzchar() 函数的唯一区别是 nchar 返回数值,而 nzchar() 返回逻辑值。考虑将 nzchar() 应用于我们在示例中创建的相同 vector0,可选参数 keepNA 设置为 FALSE。
nzchar(vector0, keepNA = FALSE)
产生的输出是
[1] TRUE TRUE TRUE
如果向量包含表示为“ ”的空字符串和非空字符串,它们将返回 FALSE 值。
请看下表
| nchar() | nzchar() | 区别 |
|---|---|---|
| vector0<- c(NA,"R", 'TUTORIAL', NULL) nchar(vector0, keepNA = FALSE) | vector0<- c(NA,"R", 'TUTORIAL', NULL) nzchar(vector0, keepNA = FALSE) | nchar() 返回一个与向量(vector0)长度相同的数值向量作为输出。 |
| [1] 2 1 8 | [1] TRUE TRUE TRUE | |
| nchar(vector0, keepNA = TRUE) | nzchar(vector0, keepNA = TRUE) | nzchar() 返回一个与向量(vector0)长度相同的逻辑向量作为输出。 |
| [1] NA 1 8 | [1] NA TRUE TRUE |
R 编程语言中的 format() 函数通过将向量对象编码为通用格式来处理所有向量元素作为字符字符串。
format(x, trim = FALSE, digits = NULL, nsmall = 0L,
justify = c("left", "right", "centre", "none"),
width = NULL, na.encode = TRUE, scientific = NA,
big.mark = "", big.interval = 3L,
small.mark = "", small.interval = 5L,
decimal.mark = getOption("OutDec"),
zero.print = NULL, drop0trailing = FALSE, ...)
其中参数
big.mark, big.interval, small.mark, small.interval, decimal.mark, zero.print, drop0trailing 用于美化(较长)数值和复杂序列。传递给 prettyNum
#use format() in R
# Place string to the left side
StrFormat1 <- format("Learn eTutorials", width = 25, justify = "l")
# Place string to the center
StrFormat2 <- format("Learn eTutorials", width = 25, justify = "c")
# Place string to the right
StrFormat3 <- format("Learn eTutorials", width = 25, justify = "r")
# Display the different string placement
print(StrFormat1)
print(StrFormat2)
print(StrFormat3)
输出
[1] "Learn eTutorials " [1] " Learn eTutorials " [1] " Learn eTutorials"
# R program to illustrate format function
# Calling the format() function over different arguments
# Rounding off the specified digits
numformat1 = format(1.45677, width = 10,digits=2)
numformat2 = format(1.45677,width = 10, digits=4)
numformat3 = format(1.45677,width = 10, justify = "r" ,digits=4)
print(numformat1)
print(numformat2)
print(numformat3)
# Getting the specified minimum number of digits
# to the right of the decimal point.
numformat3 = format(1.45677, nsmall=3)
numformat4 = format(1.45677, nsmall=7)
print(numformat3)
print(numformat4)
输出
[1] " 1.5" [1] " 1.457" [1] " 1.457" [1] "1.45677" [1] "1.4567700"
format() 中用于格式化字符串最有用的参数是
width 生成最小宽度。trim 设置为 TRUE 时不填充空格justify 取值“left”、“right”、“centre”和“none”来控制字符串中的填充。以下参数有助于控制数字的打印,
digits 小数点右侧的位数。scientific 使用 TRUE 表示科学计数法,FALSE 表示标准计数法在 R 中,函数 substr() 从整个给定输入字符串中提取并返回字符串的一部分。对于从字符串中提取部分的过程,需要考虑一个起始和停止整数。当 substr() 应用于字符串时,提取从起始整数开始,直到达到停止或结束整数。一旦达到引用的停止整数,该函数将返回提取的子字符串。
substr(x, start, stop)
其中参数
str = "hello Learn eTutorials learners"
substr(str,6,21)
从起始整数 6 和终止整数 21 提取字符串 str 后,字符串的一部分是
[1] " Learn eTutorial"
同样,向量也以相同的方式执行。考虑一个向量 str0,其中包含“hello”、“Learn”、“eTutorials”、“learners”等元素或字符串列表。
str0=c("hello"," Learn"," eTutorials"," learners")
substr(str,6,21)
R 中的 grep 函数或 grep() 有助于识别或搜索字符串中的特定模式。如果 grep 函数找到与字符串中模式相似的匹配项,它将返回搜索模式的实例数。
grep() 是 R 中用于模式匹配和替换的函数。grep、grepl、regexpr、gregexpr、regexec 和 gregexec 在字符向量的每个元素中搜索与参数模式的匹配项
sub 和 gsub 分别执行第一次匹配和所有匹配的替换。
grep(pattern, x, ignore.case = FALSE, perl = FALSE, value = FALSE,
fixed = FALSE, useBytes = FALSE, invert = FALSE)
grepl(pattern, x, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE)
其中参数
| ignore.case=TRUE | 模式匹配时忽略大小写。例如,pattern =“ Learn” 匹配所有其他可能的模式,无论其大小写表示如何,“learn”、“LEARN”等。 |
| ignore.case=FALSE | 查找匹配项时包括大小写敏感性。例如,pattern =“ Learn” 仅匹配“Learn”,而不匹配“learn”、“LEARN”等。默认情况下,对大小写敏感选项使用 FALSE。 |
| fixed=TRUE | 模式是按原样匹配的字符串,表示模式匹配必须精确 |
| fixed=FALSE | 对精确模式匹配没有限制(默认) |
| useBytes=TRUE | 按字节模式匹配 |
| useBytes=FALSE | 按字符匹配 |
| invert = TRUE | 如果为 TRUE,则返回与模式不匹配的元素的索引或值。 |
| Invert = FALSE | 如果为 FALSE,则返回与模式匹配的元素的索引或值。 |
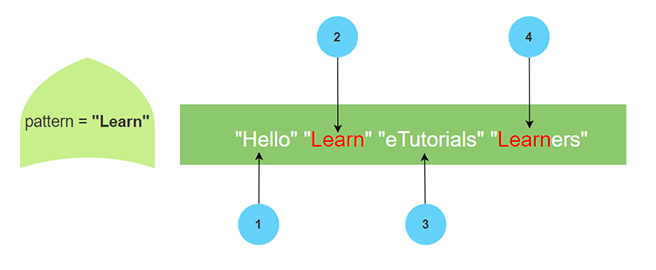
考虑下面的代码,一个名为 str0 的向量,包含以下元素:"hello"、" Learn"、" eTutorials"、" Learners"
str0=c("hello"," Learn"," eTutorials"," Learners")
假设你需要在向量 str0 中检查模式“Learn”。你可以在此处使用 grep()。
grep("Learn",str0)
在 str0 中应用 grep() 后的输出是
[1] 2 4
grep() 搜索模式并返回实例数。例如,搜索模式“Learn”返回它在 2、4 处出现的实例数。
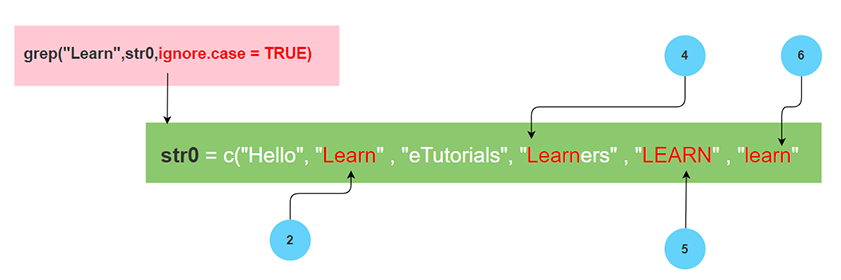
考虑输入字符向量 str0,其中包含字符元素或字符串列表。
str0=c("hello"," Learn"," eTutorials"," learners","LEARN","learN")
下表显示了 ignore.case 与 grep() 的用例
| grep("Learn",str0) | [1] 2 | 默认情况下,ignore.case 为 FALSE,在模式匹配时忽略大小写敏感的字符串。 |
| grep("Learn",str0,ignore.case = FALSE) | [1] 2 | 如果为 FALSE,则模式匹配区分大小写 |
| grep("Learn",str0,ignore.case = TRUE) | [1] 2 4 5 6 | 如果为 TRUE,则在匹配期间忽略大小写。 |
str0=c("hello"," Learn"," eTutorials"," learners","LEARN","learN")
> grep("Learn",str0,ignore.case = TRUE,value = TRUE,fixed = TRUE,useBytes = TRUE,invert =TRUE)
[1] "hello" " eTutorials" " learners" "LEARN" "learN"
上面示例中 grep() 中每个参数的描述
| 模式 | "Learn" |
| x | str0 |
| ignore.case = TRUE | 忽略大小写敏感性并返回所有匹配模式 |
| value = TRUE | 返回匹配元素本身,而不是匹配元素的索引, |
| fixed = TRUE | 返回精确匹配 |
| useBytes = TRUE | 按字节匹配 |
| invert =TRUE | 返回输出中不匹配的值。 |
在 str0 向量中应用 grep() 后的输出是
[1] "hello" " eTutorials" " learners" "LEARN" "learN"
其中这些模式与给定模式不匹配。
考虑当上述代码中的所有参数都设置为 FALSE 时会发生什么。
grep("Learn",str0,ignore.case = FALSE,value = FALSE,fixed = FALSE,useBytes = FALSE,invert = FALSE)
[1] 2
如果值为 FALSE,则返回一个包含由 grep() 确定的匹配项(整数)索引的向量。模式“Learn”与 str0 向量的索引 2 完全匹配。
另一个简单的例子是更好地理解参数值和反转。返回不匹配的元素本身,即作为字符向量。在这种情况下不返回索引。
尝试理解每个参数并观察下面给定代码的变化。
> str0=c("hello"," Learn"," eTutorials"," learners","LEARN","learN") # vector str0
> str0
[1] "hello" " Learn" " eTutorials" " learners" "LEARN"
[6] "learN"
> grep("Learn",str0) # grep() to extract pattern
[1] 2
> grep("Learn",str0,invert = TRUE) #Non matching elements are extracted using invert
[1] 1 3 4 5 6
> grep("Learn",str0,value = TRUE,invert = TRUE) #value return character vector itself not indices.
[1] "hello" " eTutorials" " learners" "LEARN" "learN"
>
R 中的 strsplit() 是一个用于分割字符向量元素的函数。strsplit() 根据语法中提供的 split 参数将给定的字符向量(字符串)x 分割成子字符串。split 参数指示用于将字符串分割成子字符串的字符向量。
strsplit(x, split, fixed = FALSE, perl = FALSE, useBytes = FALSE)
其中参数
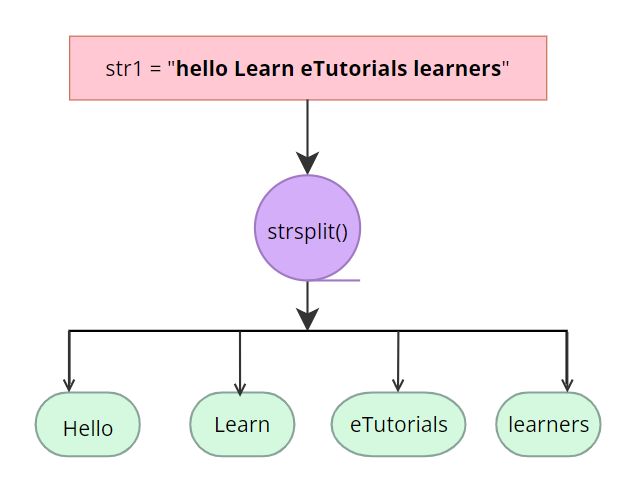
考虑字符变量或字符串 str1 "hello Learn eTutorials learners",应用 strsplit(),split 参数为“ ”,通过在空格处分割字符串 str1,返回一个字符或字符串元素列表,如 "hello" "Learn" "eTutorials" "learners"。
str1 = "hello Learn eTutorials learners"
> print(str1)
[1] "hello Learn eTutorials learners"
> strsplit(str1, " " )
[[1]]
[1] "hello" "Learn" "eTutorials" "learners"
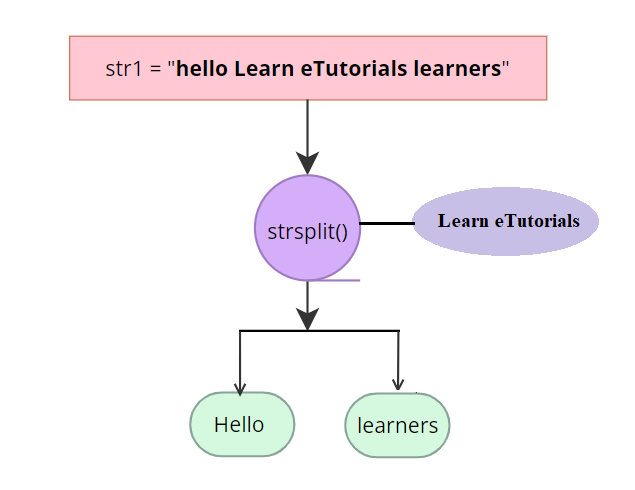
考虑另一个示例以了解 strsplit() 的目的
str1 = "hello Learn eTutorials learners"
print(str1)
strsplit(str1, "Learn eTutorials" )
字符串在 split 参数指定的位置分割,这里 split 是“Learn eTutorials”。让我们看看它的输出
[1] "hello" "learners"
R 中的 tolower() 将字符字符串转换为小写。toupper() 函数的作用与 tolower() 相反,它将字符字符串转换为大写。
| 描述 | tolower() 和 toupper() 将字符向量中的字符从大写转换为小写,反之亦然。 |
| 语法 | tolower(x) toupper(x) 其中 x 是输入字符字符串。 |
| 示例 tolower(x) | x= "HELLO" > print(x) [1] "HELLO" > tolower(x) [1] "hello" |
| toupper(x) | > x= "hello" > print(x) [1] "hello" > toupper(x) [1] "HELLO" |

