

在本教程中,您将学习 R 编程语言中名为向量的数据结构之一。与所有其他编程语言一样,数据结构是为了在计算机内存中存储用户数据以便以后引用而组织起来的结构。您将学习如何创建向量、不同的数据操作技术和用于检查向量的函数,以及更多内容。让我们来看一下。
在 R 中,向量是一种基本数据结构,本质上是同质的。同质性定义了向量只包含相同数据类型的元素。换句话说,向量是一种存储相同基本数据类型数据元素序列的数据结构。R 中的向量使用我们在上一个教程中讨论过的基本数据类型。向量可以有一个元素或一系列属于任何基本数据类型(如逻辑型、整型、数值型等)的元素。因此,向量数据结构进一步分为五类或原子类型。它们是
| 向量类型 | 描述 | 示例 |
|---|---|---|
| 逻辑型 | 取 TRUE 或 FALSE 值。 | 真或假 |
| 整型 | 取正整数和 0 等整数值。 | 0, 56, 7990 |
| 数值型 | 取整数和带小数点的数值。 | 0, 10, 0.009, 5.6 |
| 复数型 | 取带实部和虚部的值。 | 1+2i, -3+4I |
| 字符 | 取单个字符或单词序列 | “A”,“HELLO” |
R 中 c() 函数用于组合相同基本数据类型的数据元素序列。
c(<value 1>,<value 2>…………..<value n>)
c(5,45,19) #numeric
c(TRUE,FALSE) #logical
您可以将此创建的向量存储或分配给某些变量,如 vector1、vector2 等。
Vector1 = c(5,45,19)
Vector2 = c(TRUE,FALSE)
在之前的教程中,您学习了变量,例如
language <- "R programming ", "Variables in R" -> Tutorial 本身都是只包含一个元素的向量。
Vector1 = c(5,45,19) #created numeric data type vector
#assigned to variable named Vector1
Vector2 = c(TRUE,FALSE) #logical data type vector
#assigned to variable named Vector2
print(Vector1)
print(Vector2)
输出
[1] 5 45 19 [1] TRUE FALSE
a = c('john','sam','jeniffer','Alex','Paul') # Vector2 of character type
print(a)
a <- c(a, "Zain") #add element Zain at the end of vector a
print(a)
a <- c( "james",a) #add element james at the beginning of vector a
print(a)
创建了一个字符数据类型的向量 a,它包含值 'john'、'sam'、'Jeniffer'、'Alex'、'Paul'。然后使用 a <- c(a, "Zain") 和 a <- c("james", a) 向其添加两个元素,一个在末尾,一个在开头。当您执行上述代码时,它会产生以下结果。
输出
> print(a) [1] "john" "sam" "jeniffer" "Alex" "Paul" > a <- c(a, "Zain") > print(a) [1] "john" "sam" "jeniffer" "Alex" "Paul" "Zain" > print(a) [1] "james" "john" "sam" "jeniffer" "Alex" "Paul" [7] "Zain"
您可以使用名为 names() 的函数为 R 中的每个向量元素附加名称。该函数有助于通过关联的名称引用向量中的每个元素。
命名向量元素的语法
names(<vector_name1>) = <vector_name2>
让我们通过一个例子来理解。使用 c() 函数创建了两个向量 number (
number <- c(1,2,3,4) #numeric data type vector
print(number)
输出
[1] 1 2 3 4
让我们创建另一个字符串数据类型的向量 colors
colors = c('pink','yellow','blue','green') #character data type vector
print(colors)
输出
[1] "pink" "yellow" "blue" "green"
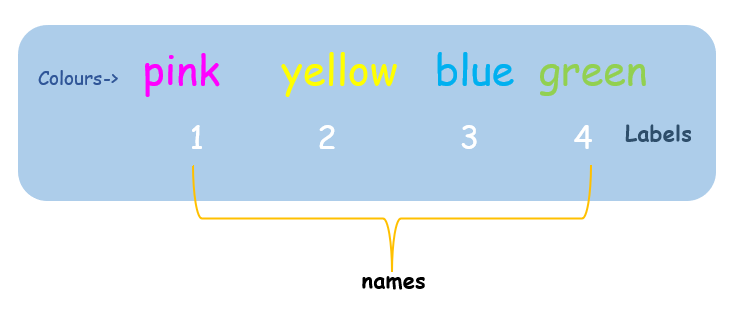
使用 names() 函数将名称分配给向量元素,即在我们的示例中 names(number) = colors。向量 colors 被分配给 names(number) 函数,该函数为每种颜色命名一个数字名称,例如“pink”为 1,“yellow”为 2 等。
让我们通过一个程序来理解
number <- c(1,2,3,4) #numeric data type vector
print(number)
colors = c('pink','yellow','blue','green') #character data type vector
print(colors
names(number) = colors # names()
print(number)
输出
[1] 1 2 3 4
[1] "pink" "yellow" "blue" "green"
pink yellow blue green
1 2 3 4
同样可以在不使用 names() 函数的情况下表示,如程序中所示
labels <- c(1,2,3,4)
colors <- c('pink','yellow','blue','green')
names(labels)<- colors
print(labels)
labels <- c('pink'=1,'yellow'=2,'blue'=3,'green'=4)
print(labels)
labels <- c(pink=1,yellow=2,blue=3,green=4)
print(labels)
输出
> labels <- c(1,2,3,4)
> colors <- c('pink','yellow','blue','green')
> names(labels)<- colors
> print(labels)
pink yellow blue green
1 2 3 4
> labels <- c('pink'=1,'yellow'=2,'blue'=3,'green'=4)
> print(labels)
pink yellow blue green
1 2 3 4
length() 函数确定向量的长度。
检查向量长度的语法
length(<vector_name>)
示例
length(labels)
length(colors)
labels <- c(1,2,3,4,5,6,7,8,9,10)
print(length(labels))
colors <- c('pink','yellow','blue','green')
print(length(colors))
当上述代码执行后,length() 函数会给出标签和颜色的长度。
输出
[1] 10 [1] 4
向量元素的提取也可以称为向量子集。用于子集的运算符是 [ ]。
在 R 编程中,可以通过在方括号 [ ] 内提供向量元素的索引号来检索向量元素,例如 <vector 名称>[索引值],例如:Vector1[1]
Vector1 = c(5,45,19) #created numeric data type vector
Vector2 = c('john','sam','jeniffer') # Vector2 of character type
Vector1[1]
Vector2[3]
Vector2[0]
输出
> Vector1[1] [1] 5 > Vector2[3] [1] "jeniffer" > Vector2[0] character(0)
您可以通过指定起始索引到结束索引来从向量中提取多个向量元素,例如 Vector1[1:3],它将返回该区间内存在的数据,如下所示
Vector1 = c(5,45,19) #created numeric data type vector
Vector2 = c('john','sam','jeniffer','Alex','Paul') # Vector2 of character type
Vector1[1:3]
Vector2[1:3]
Vector2[1:5]
输出
> Vector1[1:3] [1] 5 45 19 > Vector2[1:3] [1] "john" "sam" "jeniffer" > Vector2[1:5] [1] "john" "sam" "jeniffer" NA NA
这里的 NA 代表缺失值,我们将在接下来的教程中讨论。
在 R 中,内置函数 is.vector() 用于判断 R 程序中是否存在向量。如果存在向量,该函数返回 TRUE,如果不存在向量,则返回 FALSE。
is.vector(<vector_name>)
labels <- c(1,2,3,4,5,6,7,8,9,10)
print(is.vector(labels))
colors <- c('pink','yellow','blue','green')
print(is.vector(colors))
alphabets<- c('pink','yellow','blue','green')
print(is.vector(alphabets))
print(is.vector(names))
输出
[1] TRUE [1] TRUE [1] TRUE [1] FALSE
向量是一种数据结构,其元素或数据序列属于数值型、整型、复数型、逻辑型、字符型等原子类之一。在 R 中,不允许向量包含这些原子类的组合作为单个向量值。如果出现这种情况,R 会对向量执行强制转换。
强制转换的字面意思是“强迫某人做某事”的做法,在向量的情况下,将不同数据类型升级为相同数据类型是此 R 编程上下文中强制执行的操作。
考虑一个向量 v3,其中存储了三个不同的原子类,例如逻辑型 (FALSE)、数值型 (4.5)、整型 (67L)。
v3=c(FALSE,4.5,67L)
class(v3)
print(v3)
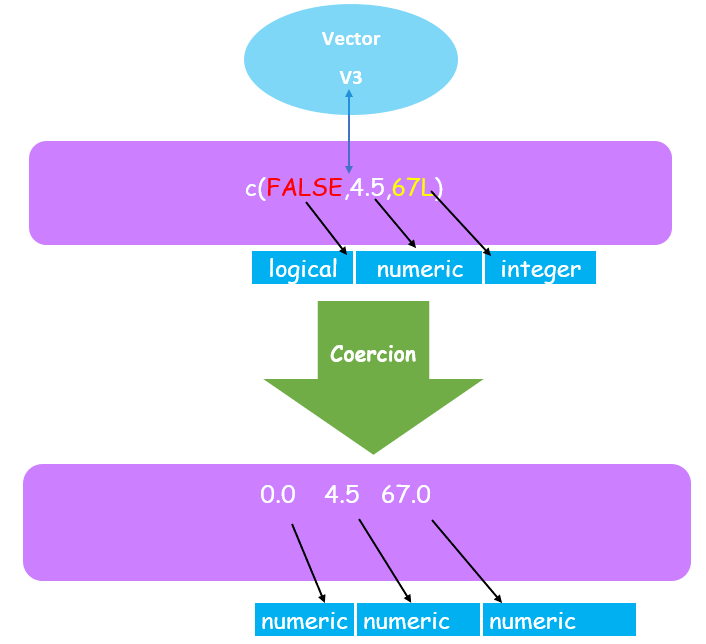
当您在 RStudio 中执行 v3 向量代码时,它会产生如下所示的输出,其中 FALSE 显示为 0.0,4.5 保持不变,整数类型 67L 转换为十进制数,如 67.0。我们可以从输出中推断出,即使在创建向量时提供了不同的数据类型,这些元素也会转换为单一类型,即数值类型。
输出
> v3=c(FALSE,4.5,67L) > class(v3) [1] "numeric" > print(v3) [1] 0.0 4.5 67.0
让我们了解当向相同的代码中添加字符类型“HELLO”和“R”时会发生什么。
v3=c(FALSE,4.5,67L,"HELLO",'R')
class(v3)
print(v3)
当您执行上述代码时,在创建向量 v3 时使用了字符数据类型以及其他类型,如 FALSE(逻辑型)、4.5(数值型)等,会产生如下所示的输出。
输出
> v3=c(FALSE,4.5,67L,"HELLO",'R') > class(v3) [1] "character" > print(v3) [1] "FALSE" "4.5" "67" "HELLO" "R" >
您可以推断出,一旦代码执行,所有给定的不同数据类型值都会转换为字符类型并作为字符数据类型存储在向量 v3 中。不同的数据类型被转换为单一类型以存储在向量中。
注意
| 函数 | 描述 |
|---|---|
| c() | 创建向量 |
| names() | 为向量附加标签 |
| typeof() | 确定向量数据类型 |
| length() | 检查向量长度 |
| is.vector() | 检查向量是否存在 |
创建的向量可以灵活地执行各种操作,例如求平均值、标准差、绘制图形等。
Vector1 = c(5,45,19) #created numeric data type vector
#assigned to variable named Vector1
mean(Vector1)
sd(Vector1)
barplot(Vector1)
输出
[1] 5 45 19 [1] TRUE FALSE > mean(Vector1) [1] 23 > sd(Vector1) [1] 20.29778 > barplot(Vector1)
让我们看看带有图形的相同片段
向量逐元素执行算术运算。向量中的每个元素都与另一个向量中的另一个元素进行操作,以产生结果输出。
v1 = c(5,6,7)
v2= c(4,4,2)
我们可以执行两个向量 v1 和 v2 的加法
v3=v1+v2
print(v3)
它产生的结果是
[1] 9 10 9
同样地,向量的减法、乘法、除法运算也进行了,总结如下表
| 操作 | 代码 | 输出 |
|---|---|---|
|
减法 |
V3 = v1-v2 |
[1] 1 2 5 |
|
乘法 |
v3=v1*v2 |
[1] 20 24 14 |
|
除法 |
v3=v1/v2 |
[1] 1.25 1.50 3.50 |

