在本教程中,我们将学习 R 编程中支持与向量数据结构操作的可用内置函数。允许用户简化 R 中处理向量数据结构任务的函数称为向量函数。在本教程中,我们将详细通过示例理解每个向量函数概念及其在 R 程序中的用法。

向量函数是允许创建或操作 R 中常用数据结构(称为向量)的函数。向量函数在已定义的向量上操作以执行某些特定操作。有不同的可用函数,每个函数都有特定的唯一特征。
R 编程语言中的向量函数列表是
在 R 编程语言中,rep() 函数是复制向量元素以及复制列表中元素的函数。它是一个泛型函数,具有以下语法。
rep(x, ...)
rep.int(x, times)
rep(x,each)
rep_len(x, length.out)
其中参数
| 参数 | 描述 |
|---|---|
| x | 是一个向量。 |
| … | x 后面跟着的点表示要传递给其他方法(如 times、length.out)或从其他方法传递的进一步参数。 |
| times | 是 x 后面的一个参数,用于指示向量应重复的次数。 |
| length.out | 是用于获得所需长度向量输出的参数。 |
| each | 参数允许每个元素连续重复指定的次数。 |
Vector1 = c(5,45,19)
print(Vector1)
考虑使用 c() 函数创建的名为 Vector1(语法中的 x)的向量,以获得如下所示的输出。
[1] 5 45 19
我们创建了一个向量 Vector1,现在让我们在向量上应用 rep() 函数来重复向量中的元素。Vector1 的元素分别是 5、45 和 19。
#syntax rep(x,times)
rep(Vector1,times =3)
rep.int(Vector1,times =3)
带有任何非负整数赋值的 times 参数会导致向量重复该次数。这里 times 被赋值为 3,表示整个向量必须重复 3 次。让我们看看执行上述代码后的输出。
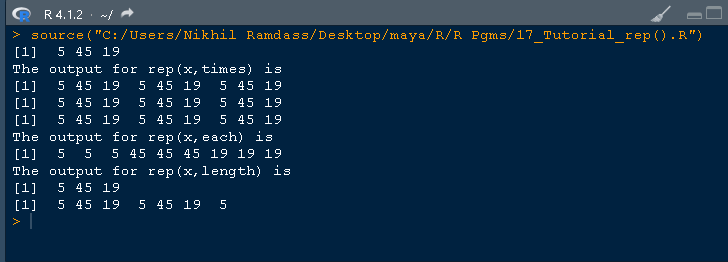
> rep(Vector1,times =3) [1] 5 45 19 5 45 19 5 45 19 > rep.int(Vector1,times =3) [1] 5 45 19 5 45 19 5 45 19 >
从输出中,您会注意到 rep(Vector1,times =3) 和 rep.int(Vector1,times =3) 的两种语法都产生相同的结果。
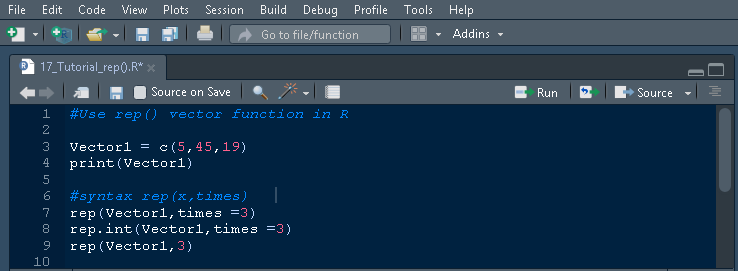
屏幕截图显示了 rep() 使用 times 的不同表示,这些表示产生了相同的输出。
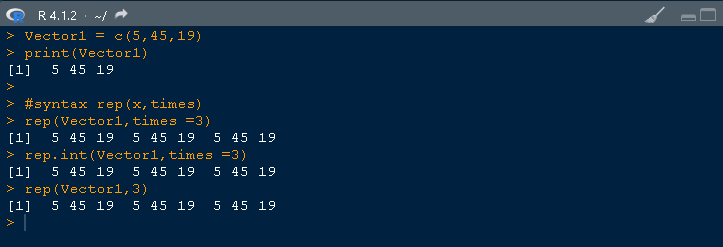
接下来,看看 rep() 函数中使用的 each 参数。
rep(Vector1,each=3)
向量中的每个元素都会根据指定的数量重复。这里 each 设置为 3。所以每个元素都会重复 3 次,如下所示。
> rep(Vector1,each=3) [1] 5 5 5 45 45 45 19 19 19
接下来是 length.out 参数在 rep() 中的功能。给定向量的重复会一直发生,直到它达到 rep 函数中指定的长度。
此外,还通过使用两种不同的语法来获得相同的结果,如下所示:
#length argument
rep(Vector1,len=)
rep_len(Vector1, length.out=)
使用具有给定不同长度参数的 rep() 语法,可以生成以下输出。
> Vector1 = c(5,45,19) > print(Vector1) [1] 5 45 19 > rep(Vector1,len=1) [1] 5 > rep(Vector1,len=2) [1] 5 45 > rep_len(Vector1, length.out=3) [1] 5 45 19 > rep_len(Vector1, length.out=4) [1] 5 45 19 5 > rep_len(Vector1, length.out=5) [1] 5 45 19 5 45 > rep_len(Vector1, length.out=6) [1] 5 45 19 5 45 19 > rep_len(Vector1, length.out=10) [1] 5 45 19 5 45 19 5 45 19 5 >
给出的屏幕截图使您能够可视化这些代码在 RStudio 中的样子。
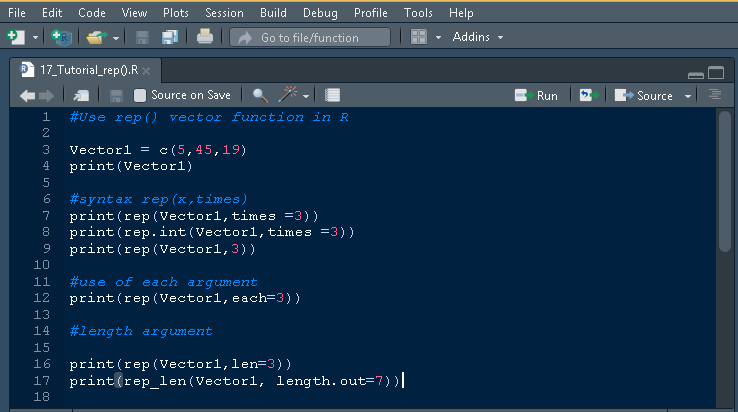
结果输出
rep() 函数的默认行为可总结为
rep(x, times = 1, length.out = NA, each = 1)
示例
> rep(Vector1, times = 1, length.out = NA, each = 1)
[1] 5 45 19
> rep(Vector1, times = 4, length.out = 5, each = 2)
[1] 5 5 45 45 19
>
R 中的 seq() 函数用于生成规则序列。seq() 特别用于向量数据结构。R 中的 seq() 函数在 R 编程语言中创建值序列。
让我们看看语法以了解更多关于 seq(………..) 的功能。
seq(………….)
seq(from = 1, to = 1, by = ((to - from)/(length.out - 1)),
length.out = NULL, along.with = NULL, ...)
seq.int(from, to, by, length.out, along.with, ...)
seq_along(along.with)
seq_len(length.out)
其中
| 参数 | 描述 |
|---|---|
| from | 序列的起始值 |
| to | 序列的结束值 |
| by | 序列的间隔 |
| length.out | 序列的期望长度。一个非负数,对于 seq 和 seq.int,如果为小数则向上取整。 |
| along.with | 从该参数的长度获取长度。 |
典型用法是
seq(from, to)
seq(from, to, by= )
seq(from, to, length.out= )
seq(along.with= )
seq(from)
seq(length.out= )
seq(x) 是最简单的函数之一,seq() 中可以使用许多附加参数,我们将在本节中讨论。
#use seq() function in R
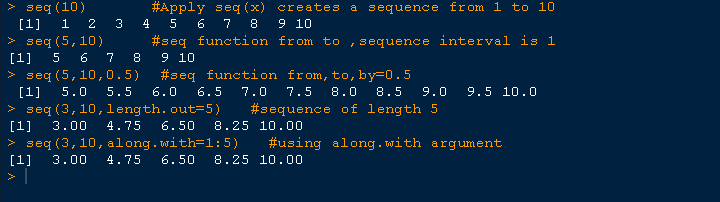
seq(10) #Apply seq(x) creates a sequence from 1 to 10
seq() 函数对数字 10 执行后,输出从 1 开始到 10 结束生成一个数字序列,如下所示。
[1] 1 2 3 4 5 6 7 8 9 10
seq(5,10) #seq function from to
seq 语法包含 from 和 to 参数。From 指示向量的开始,to 指示向量的结束,序列将在其上生成。在我们的示例中,给出了起始点 5 (from) 和结束点 10 (to),seq() 生成另一个数字序列,如下所示。序列的间隔为 1。
[1] 5 6 7 8 9 10
通过向 seq() 添加 by 参数可以更改序列间隔。在先前的示例中,间隔为 1。(6-5=1、7-6=1……10-9=1,类似 to-from)。by 设置了其序列生成期间元素之间的间隔。在我们给出的示例中,by = 0.5,因此数字序列的生成彼此之间的差异为 0.5。我们需要在 seq() 中指定起始点 (from) 和结束点 (to) 以及 by 参数。
seq(5,10,0.5) #seq function from,to,by=0.5
结果输出是
[1] 5.0 5.5 6.0 6.5 7.0 7.5 8.0 8.5 9.0 9.5 10.0
带有 length.out 参数的 seq() 函数指定了参数应该有多长,您需要同时指定 from 和 to 来生成序列。
seq(3,10,length.out=5) #sequence of length 5
当这段代码运行时,它生成一个长度为 5 的序列,因为 length.out = 5。这个序列的间隔取决于需要创建的元素数量。
[1] 3.00 4.75 6.50 8.25 10.00
产生的结果与上述语法相同,只是参数有所不同。
seq(3,10,along.with=1:5) #using along.with argument
输出是
[1] 3.00 4.75 6.50 8.25 10.00
屏幕截图展示了生成序列的不同语法的总结。
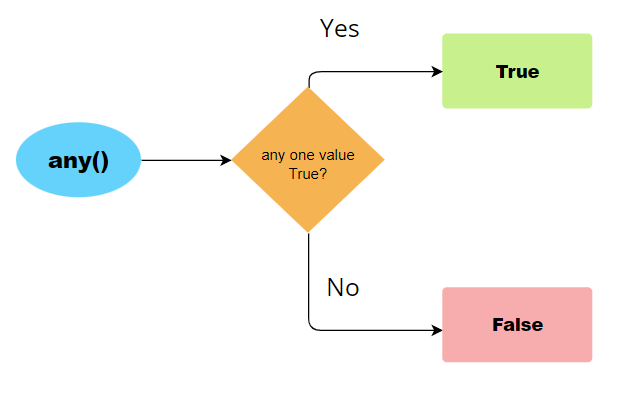
any() 函数用于查找给定逻辑向量集是否至少有一个值为真。any() 函数用一个输入向量和一个需要满足的条件括起来。在 any() 的情况下,如果向量中的任何元素满足给定条件,则返回布尔值 TRUE。否则,返回 FALSE。
any(..., na.rm = FALSE)
其中
| 参数 | 描述 |
|---|---|
| ... | 零个或多个逻辑向量。零长度的其他对象将被忽略,其余将被强制转换为逻辑值,忽略任何类。 |
| na.rm | 逻辑值。如果为 TRUE,则在计算结果之前移除 NA 值。 |
在下面的示例中,创建了一个向量 x 并提供了一个条件 (x<4)。any 函数或 any() 检查 x (向量) 的任何值是否满足给定条件,如果满足,则返回布尔值 TRUE 或 FALSE。
# use any() function
x = c(2,5,6,-9,-12,-16)
print(x)
print(any(x<4))
输出将是布尔值 TRUE,因为 2、-9、-12 和 -16 都小于 4。该函数只检查是否有任何值满足条件。
[1] 2 5 6 -9 -12 -16 [1] TRUE
让我们用 NA 值再看一个例子。
# use any() function
x = c(2,5,6,NA,-9,-12,-16)
print(x)
print(any(x<4,na.rm=TRUE))
na.rm 的值为 TRUE 意味着在计算结果之前会移除 NA 值。
它产生与上面相同的结果,因为我们示例中的条件保持不变。根据我们的输入向量和条件,any() 函数的输出会有所不同。
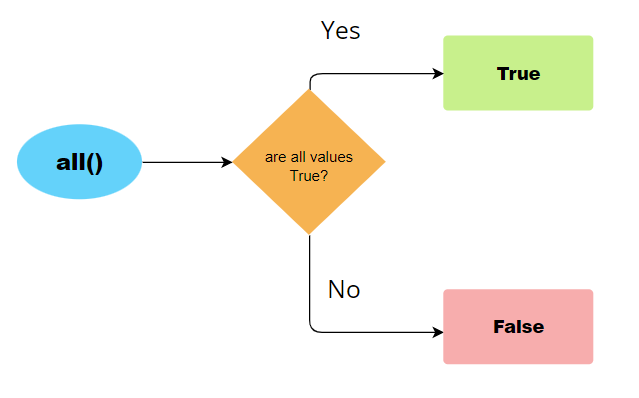
all() 函数用于查找给定逻辑向量集是否所有值都为真。all() 函数将其参数(作为输入向量和需要满足的条件)括在所有括号 () 中。如果向量中的所有元素都满足条件,则返回 TRUE。另一方面,如果没有任何元素、任何元素或单个元素不满足条件,则返回布尔值 FALSE。所有元素都应满足条件才能返回 TRUE。
any(..., na.rm = FALSE)
其中
| 参数 | 描述 |
|---|---|
| …… | 零个或多个逻辑向量。零长度的其他对象将被忽略,其余将被强制转换为逻辑值,忽略任何类。 |
| na.rm | 逻辑值。如果为 TRUE,则在计算结果之前移除 NA 值。 |
考虑示例。
x1=c(1,2,3,4,5)
print(all(x1<6))
代码执行后返回 TRUE,因为向量 x1 的所有值都小于 6,所以所有向量都满足条件。
[1] TRUE
相反的条件 all x1>6 会返回布尔值 FALSE 输出,如下所示。
print(all(x1>6))
[1] FALSE
在 R 中,内置函数 is.vector () 用于确定向量是否存在于 R 程序中。如果存在向量,该函数返回 TRUE,如果不存在向量,则返回 FALSE。
is.vector 已在向量教程中讨论过。请查看 is.vector() 函数。
在 R 中,as.vector() 是一个内置函数,用于将任何其他数据结构(如矩阵、数组等)转换为向量数据结构。它是一个泛型函数,尝试将其实参强制转换为向量模式。
as.vector(x, mode = "any")
其中参数
| x | 是一个 R 对象 |
| mode=” any” | 它是一个字符字符串,给出原子模式或“list”,或(除了‘vector’之外)“any”。 |
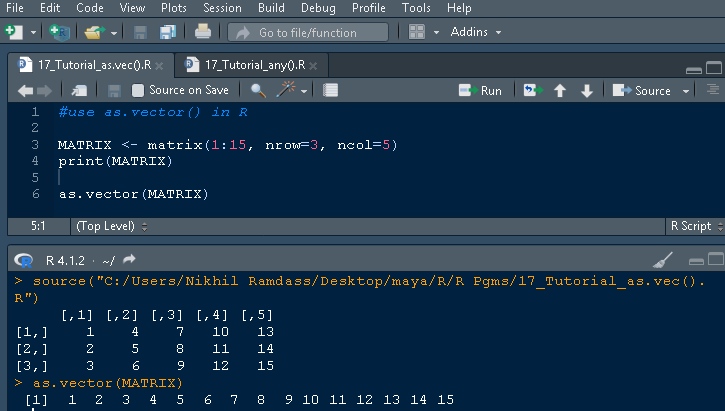
考虑使用矩阵的示例。创建了一个需要转换为向量数据结构的矩阵。
MATRIX <- matrix(1:15, nrow=3, ncol=5)
print(MATRIX)
创建的矩阵是
[,1] [,2] [,3] [,4] [,5] [1,] 1 4 7 10 13 [2,] 2 5 8 11 14 [3,] 3 6 9 12 15
使用 as.vector 将 3x5 的矩阵 MATRIX 转换为一维向量,如下所示。
as.vector(MATRIX)
输出是
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
下面是使用 as.vector() 将矩阵转换为向量的屏幕截图。