

在我们上一个教程中,我们讨论并学习了 R 中的数据框。在本教程中,您将学习一种称为因子的特殊数据结构。因子最重要用途之一是统计建模。
具有统计学背景的人可能了解分类变量。分类变量与数值变量不同,它们只能取有限数量的不同值。否则,分类变量只能属于有限数量的类别。例如,在数据分析中,是/否、真/假、男/女是分类变量的一些类型。
R 是一种支持特定数据结构的编程语言,称为因子。当您将分类数据存储为因子时,您可以确保所有统计建模技术都能有效地处理此类数据。
在深入学习因子教程之前,您需要了解分类变量的概念。您熟悉数据集这个词,数据集是数据的集合。R 编程语言使用数据集来处理、存储和分析数据,以进行数据分析和统计建模。这些数据集主要包含两种类型的变量:
连续变量是其值无限的变量。换句话说,它们包含不可数的值集。例如,温度、星系中的恒星数量、我们的体重都是连续变量。它可以在一个区间内取任何指定的值。
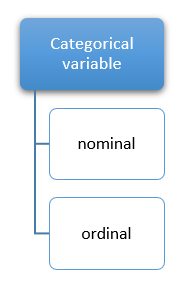
分类变量或离散变量是其值有限或包含一个不同组的变量。这意味着它们包含一个有限值集,可能有两个或多个类别(值)。分类变量有两种类型:**标称型**和**有序型**。
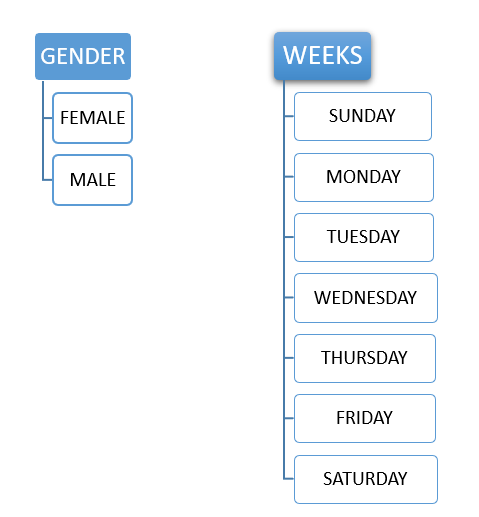
考虑 GENDER,它构成了一个标称型分类变量,因为它的值只有两种可能,即 MALE 或 FEMALE。没有任何排序约束,无论 male 还是 female 都可以排在第一个位置。同样,考虑 WEEKS,weeks 只有 7 个值或类别,如 SUNDAY、MONDAY、TUESDAY、WEDNESDAY、THURSDAY、FRIDAY、SATURDAY。
TEMPERATURE 可以分为 LOW、MEDIUM 和 HIGH 三类。它属于有序类别。值有一个特定的排序,从低温开始,然后是中温,最后达到高温。
理解分类变量是学习 R 编程中因子之前的基本部分。在下一节中,我们将开始学习新的数据结构。
因子是 R 编程中的一种特殊数据结构,用于存储分类变量或数据。因子是用于对数据进行分类并将其存储为级别的 Sata 对象。它可以存储整数和字符串。当分析具有唯一值的列时,因子非常有用。R 允许我们在有序因子和无序因子之间进行区分。
因子可以描述为:
例如,人们的血型是一个分类变量。它可以是 A、B、AB 和 O。假设您询问了 8 个人他们的血型,并记录了信息。假设您将收集到的信息存储为向量 **blood**。
#create a vector blood using c()
blood <- c("A","B","AB","O","AB","A","O","B")
print(blood)
该向量只包含一组预定义的值。
[1] "A" "B" "AB" "O" "AB" "A" "O" "B"
在 R 编程语言中,因子数据结构是使用一个称为 **factor()** 的内置函数创建的。**factor()** 函数接受一个向量作为输入。因子函数 **factor()** 从输入向量的分类变量创建因子。
因子具有与其中存储的唯一整数相关联的 **标签**。它们包含一组预定义的值,称为 **级别**。这些级别默认按字母顺序排序。不要混淆标签和级别,您将在接下来的会话中理解。
factor(<x>,<levels>,<labels>,<exclude>,<ordered>,<nmax>)
其中 x、levels、labels、exclude、ordered、nmax 是因子的属性。
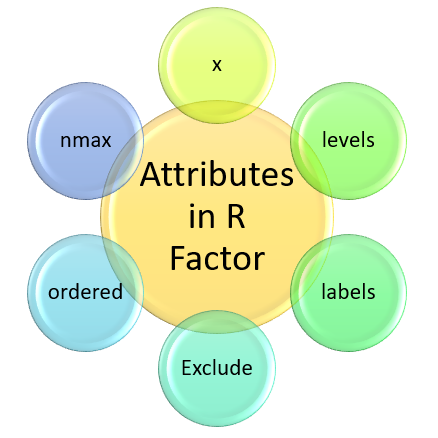
| 属性 | 描述 |
|---|---|
| X | X 是输入向量,使用 **factor()** 转换为因子。 |
| levels | 级别表示一组唯一值,默认情况下取自输入向量 (x)。 |
| labels | 它是与每个整数或数字排序相对应的字符向量。 |
| exclude | 它指定需要从因子级别中排除的值。 |
| ordered | 逻辑属性,用于确定级别是有序因子还是无序因子。 |
| nmax | 它指定了最大级别的上限。 |
示例:考虑我们在上面的会话中创建的示例 blood 中的输入向量。可以使用 factor() 来创建基于输入向量 blood 的因子。此处语法仅使用属性 X 作为输入向量。
blood 是对应于属性 X 的输入向量。
factor(blood)
此代码将产生如下所示的输出:
[1] A B AB O AB A O B Levels: A AB B O
输出不包含双引号,不像上面主题下的向量 blood。在输出中,您可以确定对应于不同血型类别的级别。在用户未指定的情况下,级别由 R 默认设置为 A AB B O。
程序员或用户也可以在创建因子时通过传递 level 参数来设置级别的顺序。以下是在因子语法中指定级别的步骤:
Factor(<name of vector> ,level = c())
#set level
factor(blood,level = c("O","A","AB","B"))
此代码将产生带有预定义级别的输出。
[1] A B AB O AB A O B Levels: O A AB B
level = c("O", "A", "AB", "B") 是创建的向量,它为输入 A B AB O AB A O B . 提供了唯一值。让我们比较输出以理解在 R 中创建因子数据结构时,有级别和无级别的区别。随 factor() 函数一起提供的 level = c("O", "A", "AB", "B")
使用用户定义的值设置级别。输入向量 blood 的默认级别为 Levels: A AB B O
而设置级别后,则为 Levels: O A AB B
| 无级别 | 有级别 |
|---|---|
| factor(blood) | factor(blood, level = c("O","A","AB","B")) |
|
[1] A B AB O AB A O B Levels: A AB B O default |
[1] A B AB O AB A O B Levels: O A AB B 程序员设置的级别 |
现在让我们看看如何为因子添加标签。标签是 factor() 函数中提供的可选向量,用于标记向量中的级别。带标签的因子指定了类别的新名称,在我们的示例 blood 中,这间接意味着标签更改了级别名称,如果级别发生更改,也会影响我们输入向量的名称。这是因为级别和相关的输入向量是相关联的。
Factor(<name of vector> ,level = c(),label = c())
#set label
factor(blood,level = c("A","B","AB","O"),label =c("BG_A","BG_B","BG_AB","BG_O"))
此代码将通过重命名因子元素来产生输出。
[1] BG_A BG_B BG_AB BG_O BG_AB BG_A BG_O BG_B Levels: BG_A BG_B BG_AB BG_O
label 参数根据下图重命名了 factor() 元素,A 重命名为 BG_A,B 重命名为 BG_B,依此类推。
| A | B | AB | O | AB | A | O | B |
| BG_A | BG_B | BG_AB | BG_O | BG_AB | BG_A | BG_O | BG_B |
当您对字符向量调用因子函数时,R 会执行两项操作:
这些整数对应于显示因子时使用的一组字符值。这可以通过显示结构来检查。可以使用 R 提供的内置函数 **str()** 来显示结构。
str(factor(blood))
它会产生一个输出,确定您正在处理的因子的结构,并显示有 4 个级别。
Factor w/ 4 levels "A","AB","B","O": 1 3 2 4 2 1 4 3
A 被编码为 1,因为它是第一个级别。AB 被编码为 2,它是第二个级别,依此类推。
请看图片以获得更清晰的图景。
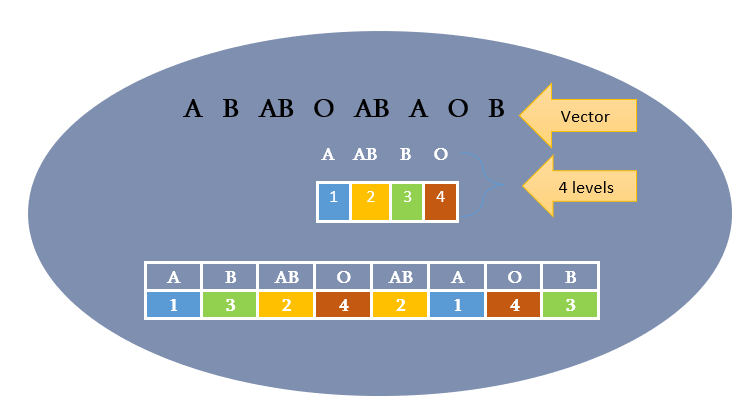
假设这些分类变量或向量可能包含长字符字符串。每次重复字符字符串可能需要大量内存。通过将字符转换为整数,实际上是用数值“A”对应 1 等来编码字符,这使其更简单且内存占用更少。
因此,R 会自动从您传入的向量推断因子级别,并按字母顺序对它们进行排序。R 还提供了设置级别顺序的机制。也就是说,可以通过在因子函数中传递 **level 参数** 来指定不同的级别顺序。
str(factor(blood, levels = c("O","B","AB","A")))
您可以看到 factor() 函数中的 level 参数指定了血型顺序。这里,“O”血型设置为级别 1,“B”血型设置为 2,“AB”为 3,“A”为 4。
Factor w/ 4 levels "O","B","AB","A": 4 2 3 1 3 4 1 2
当您比较不带级别参数和带级别参数的 factor() 的结构时,您会发现编码现在不同了。

在 R 语言中,有一些内置函数允许用户获取有关 R 程序中使用到的因子的信息。下表描述了 R 中不同可用函数的函数功能。
| 函数 | 描述 |
|---|---|
is.factor() |
用于确定一个变量是否为因子 |
as.factor() |
将输入作为向量转换为因子。 |
is.ordered() |
用于确定一个因子是否有序 |
ordered() |
用于创建有序因子 |
在本教程的下一节中,您将详细了解每个函数。让我们开始讨论 ordered() 函数。
在 R 中,因子被分为有序和无序。默认情况下,R 为因子提供顺序。在某些情况下,level = c() 允许用户预定义输入向量的顺序。我们在上面会话的“如何创建因子”主题中用一个示例讨论了这一点,请回顾一下。
这里的想法是在 A 中引入 ordered() 函数。ordered() 函数允许创建有序因子。语法与我们创建 factor() 函数的方式相似。
ordered(<name of vector> ,level = c())
考虑输入向量 X 为 blood
#create a vector blood using c()
blood <- c("A","B","AB","O","AB","A","O","B")
使用 ordered 函数语法对输入向量 blood 进行排序
#set order
ordered(blood,level = c("O","A","AB","B"))
应用 ordered() 函数后的结果输出为:
[1] A B AB O AB A O B Levels: O < A < AB < B
在 R 编程语言中,内置函数 is.factor() 确定传递给函数的对象是否属于 R 中的因子。它会返回逻辑值 TRUE 或 FALSE 作为 is.factor() 的结果。您需要在函数括号 ( ) 中传递需要确定的对象或向量的名称。
is.factor(<object name to check >)
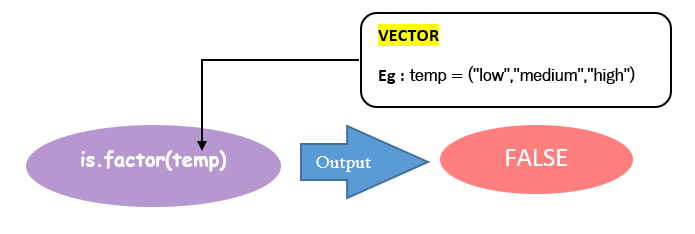
例如:下图检查 temp 是否为因子,将向量 temp 作为参数传递到 is.factor() 中。输出为 FALSE,因为 temp 只是使用 c() 函数创建的向量。
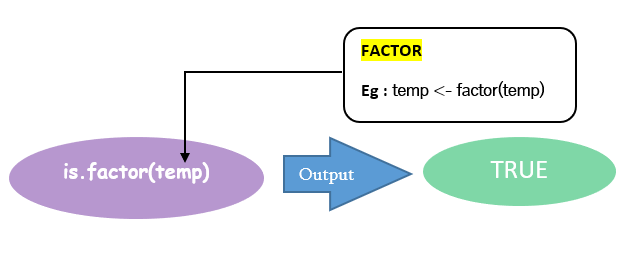
您可以使用 factor() 函数将此向量(temp)转换为因子。然后应用 is.factor() 将得到逻辑 TRUE 作为结果。请注意,创建的因子被赋值给名为 TEMP 的新向量。
识别对象为因子的步骤是:
创建了两个向量 temp 和 TEMP 来观察每种情况的差异,方法是比较它们各自的输出。
| 步骤 | 描述 | R 代码 | 输出 |
|---|---|---|---|
| 1 | 使用 c() 创建一个包含分类值 low, medium, high 的温度向量 temp。 | > temp = c("low","medium","high") > temp | [1] "low" "medium" "high" |
| 2 | 使用 is.factor() 检查对象向量是否为因子 | is.factor(temp) | [1] FALSE 表示不是因子 |
| 3 | 使用 factor() 将向量 temp 转换为因子,并赋值给变量 TEMP。 | TEMP <- factor(temp) | [1] low medium high Levels: high low medium |
| 4 | 再次使用 is.factor() 检查向量 TEMP(对象)是否为因子 | is.factor(TEMP) | [1] TRUE |
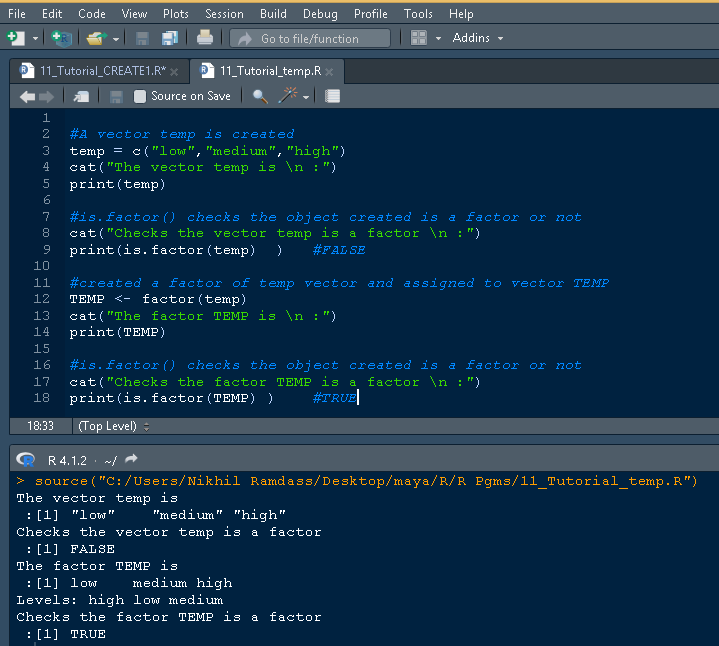
让我们看看完整的源代码
#A vector temp is created
temp = c("low","medium","high")
cat("The vector temp is \n :")
print(temp)
#is.factor() checks the object created is a factor or not
cat("Checks the vector temp is a factor \n :")
print(is.factor(temp) ) #FALSE
#created a factor of temp vector and assigned to vector TEMP
TEMP <- factor(temp)
cat("The factor TEMP is \n :")
print(TEMP)
#is.factor() checks the object created is a factor or not
cat("Checks the factor TEMP is a factor \n :")
print(is.factor(TEMP) ) #TRUE
The vector temp is :[1] "low" "medium" "high" Checks the vector temp is a factor :[1] FALSE The factor TEMP is :[1] low medium high Levels: high low medium Checks the factor TEMP is a factor :[1] TRUE
RStudio 中相同的代码片段和输出如下所示:
R 编程语言支持将变量的数据类型转换为因子或分类变量。as.factor() 函数允许将基本数据类型的字符/数值/整数变量(链接到基本数据类型)转换为因子数据结构。
as.factor(x)
其中 x 是输入向量或变量。
例如,考虑 blood 变量的字符数据类型输入向量 (X),让我们使用 c() 函数创建向量 blood,其中包含字符数据类型的值。
#create a vector blood using c()
blood <- c("A","B","AB","O","AB","A","O","B")
让我们使用 as.factor() 将向量 blood 转换为因子。
#as.factor()
as.factor(blood)
[1] A B AB O AB A O B Levels: A AB B O
factor() 函数以及 as.factor() 函数都将特定数据类型的变量返回为因子。as.factor() 的性能优于 factor() 函数。is.factor() 返回一个快速值。
R 编程语言中的内置函数 is.ordered() 允许用户检查已定义的因子是否有序或无序。根据确定因子变量,返回逻辑 TRUE 或 FALSE 作为输出。如果变量是因子,则返回 TRUE,否则返回 FALSE。
is.ordered(x)
我们在上一节创建了因子形式的 blood 变量,我们将在其中检查它是否有序。
#create a vector blood using c()
blood <- c("A","B","AB","O","AB","A","O","B")
#creates a factor
factor(blood)
#is.ordered()
is.ordered(blood)
[1] A B AB O AB A O B Levels: A AB B O [1] FALSE
输出返回 FALSE,表明因子无序。因子可以通过在创建因子时向 factor() 函数添加 levels 属性,或者使用 ordered() 函数来使其有序,ordered() 函数看起来与 factor() 函数相似但有所不同。回顾本教程的以上主题,我们已经在此处通过示例进行了讨论。
在 R 中,exclude 参数用于排除因子中的元素。
考虑使用 factor() 函数创建的 TEMP 温度因子示例
#created a factor of temp vector and assigned to vector TEMP
TEMP <- factor(temp)
cat("The factor TEMP is \n :")
print(TEMP)
The factor TEMP is :[1] low medium high Levels: high low medium
上面的代码生成了一个因子数据结构 TEMP,其中包含 low、medium、high 因子,并且默认情况下,其级别指定为 high、low、medium。
现在,让我们像处理 level 和 labels 一样,将 exclude 参数包含到 factor() 函数中。exclude 参数包含需要从 TEMP 因子中删除的元素或因子。在这里,在我们的示例中,medium 被删除,因此它被赋给了双引号内的 excluded 参数。
TEMP <- factor(temp,exclude = "medium")
让我们看看排除 TEMP 因子中的 medium 后原始输出会发生什么。
[1] low <na> high Levels: high low
在输出中,您可以看到 medium 被排除,其位置用 R 编程语言中的保留词
要生成因子级别,有一个内置函数 gl()。gl() 函数接受三个参数:u、v、labels。
gl(u,v,labels)
其中 u 是获取的级别数,V 是复制数,'labels' 是需要传递的向量。
以示例为例,它包含 3 个级别 (u),复制次数指定为 2 (v),并创建一个包含 low、high、medium 元素的向量并将其传递给 labels 参数。
gl(3,2,labels = c("low","medium","high"))
[1] low low medium medium high high Levels: low medium high
> gl(3,2,labels = c("low","medium","high"))
[1] low low medium medium high high
Levels: low medium high
> gl(3,2,labels = c("low","medium","high","average"))
[1] low low medium medium high high
Levels: low medium high average
> gl(4,2,labels = c("low","medium","high","average"))
[1] low low medium medium high high average average
Levels: low medium high average
在 R 编程语言中,可以通过方括号 [ ] 加上组件的索引号来访问因子中的任何组件。因此,索引有助于在 R 中访问因子的组件。
<name of factor>[<index number of component>]
考虑本教程开头讨论的人的血型示例。我们将首先创建向量 blood,其中包含 8 种血型作为组件,并且默认情况下也会生成相应的级别。
> blood <- c("A","B","AB","O","AB","A","O","B")
> factor_blood = factor(blood)
> factor_blood
[1] A B AB O AB A O B
Levels: A AB B O
现在让我们看看如何访问名为 factor_blood 的因子中的第四个组件。
factor_blood[4]
代码返回第四个(第 4)位置的元素。请记住,R 中的索引从 1 开始,而不是像其他语言那样从 0 开始。
[1] O Levels: A AB B O
下图显示了 8 个组件 A、B、……、B 中,第四个位置的 O 组件被检索出来了。

如果您想从创建的因子中访问多个组件,可以按向量的形式传递所需的组件索引号,通过创建 c()。
factor_blood[c(1,5)]
[1] A AB Levels: A AB B O

当您在索引号前加上负号时会发生什么?
factor_blood[-1]
您将获得如下所示的输出:
[1] B AB O AB A O B Levels: A AB B O
通过在方括号中指定 -1,可以检索除第一个位置之外的所有元素。
![factor_blood[-1] img](../assets/images/r/factors/image11.png)
factor_blood[-5]
上面的代码从因子中删除了第五个组件 AB。比较输出和我们之前示例中使用的图片。
[1] A B AB O A O B Levels: A AB B O
在 R 编程中修改或更改组件的过程非常简单。您需要像我们在上一主题中讨论的那样访问因子的组件,在使用访问语法后,指定要分配给该特定组件的新值。
<name of factor>[index number] = <value to assign>
在给出的示例中:
factor_blood[1]="AB"
该代码修改了 factor_blood 因子中的第一个组件,它用分配给它的新血型“AB”替换了原始组件“A”。

