

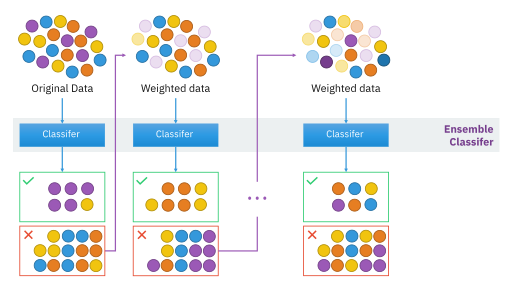
我们之前讨论了一种统计方法,用于优化决策树集成模型的性能:Bagging和随机森林。这些算法并行训练CART模型,并在最后汇总结果。
然而,另一种名为Boosting的树算法子系列采用了完全不同的方法,通过顺序训练多棵树。这些树是**弱学习器**——它们是只有单个分割的树。然而,从这些弱学习器聚合的知识将用于调整模型权重,以迫使模型随着时间的推移学习得更好。
在本教程中,我们将讨论什么是Boosting以及Boosting的不同类型。
**Boosting**通过迭代校正权重来优化朴素树模型,并在每次迭代中改进模型,简单来说,Boosting是一种方法或算法集合,有助于使弱学习器变得更强。
这意味着Boosting方法可以通过串联构建弱分类器树来从多个弱分类器树创建强分类器树。在Boosting中,树的构建从训练数据集开始。
从可用的训练集中,Boosting方法创建第一个模型,该模型可能存在许多错误。其次,Boosting技术创建第二个模型,以帮助清除第一个模型的错误。同样,第三个模型被添加,并一直持续下去,直到所有数据集的预测都完美无误,或者添加了最大数量的模型或树。
现在让我们通过一个例子来清楚地理解Boosting的概念。让我们以检查消息是否是垃圾邮件的例子。为了检查消息是否是垃圾邮件,我们制定了一些规则来对消息进行分类,例如:
现在我们有五个条件来检查消息是否是垃圾邮件。你认为这些条件单独足以检查消息是否是垃圾邮件吗?答案是否定的,所以我们可以将这些条件称为**弱学习器**。
因此,Boosting在这些场景中出现,它结合了弱学习器,使其完美地给出正确的输出。Boosting使用这些单独的条件来检查垃圾邮件,并将它们组合起来形成一个强大的条件来检查消息垃圾邮件。它使用的方法包括:
Boosting算法有不同的变体。在查看Boosting算法之前,我们必须记住,Boosting不是一个特定的算法,它作为一个通用方法,有助于改进特定的模型。在Boosting中,我们必须选择我们将要使用的模型,例如回归或决策树,Boosting需要改进这些模型。
我们将介绍两种传统的分类和回归方法,以及一种针对性能优化的现代Boosting方法。
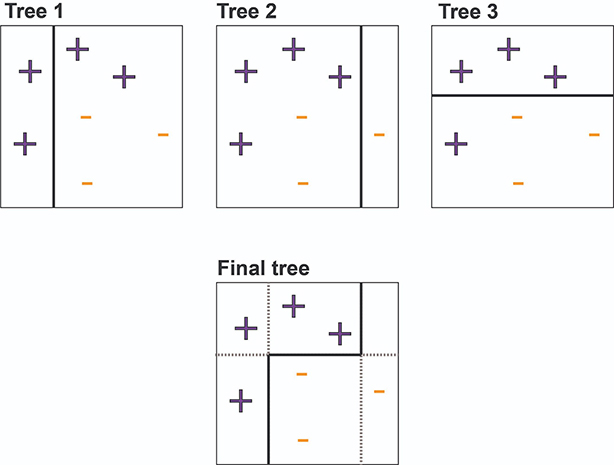
**自适应Boosting或AdaBoost**是原始的Boosting分类器,它选择可以提高模型预测能力的特征。AdaBoost通过构建决策残差(具有单个分割的独立决策树,如上图中的每个独立树所示)来工作。
如您所见,单个残差并不是很好的分类器。然而,在AdaBoost方案中,错误分类的数据点被加权。在构建完这些树后,这些弱学习器的权重被添加起来。从所有这些弱学习器构建的最终模型可以找到复杂的决策边界,从而准确地分类数据点。
从上图中,检查树1,其中每个数据点(如加号和减号)都被赋予了相等的权重,我们还可以看到一条直线表示的决策残差,用于分类数据点。
从图中我们可以看出分类不正确,因为并非所有的加号都在决策残差内。现在我们给加号添加更高的权重,并创建另一个**决策残差**。
请注意图2,我们为加号添加了更多权重并绘制了另一个决策残差,但它也不是正确的预测,因为一些减号也在残差内部,这可能会导致分类错误。因此,我们为这些减号添加了一些权重并绘制了另一个决策残差。
同样,在图3之后,通过组合前三个单独的树,我们将得到图4中所示的完美分类。Adaboost的工作原理是将弱个体学习器组合起来形成一个强大的学习器。
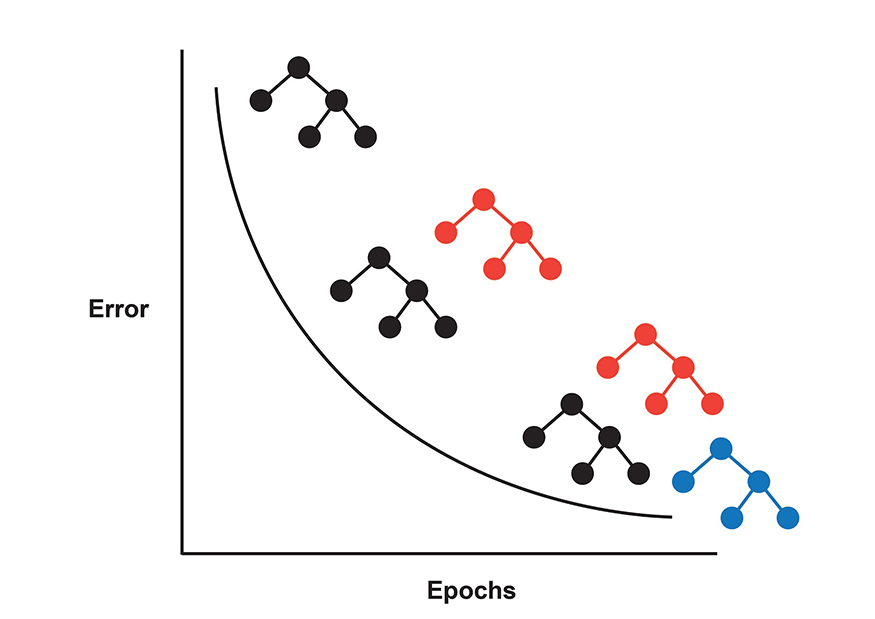
梯度Boosting是另一种Boosting变体。然而,AdaBoost和梯度Boosting之间的主要区别在于,AdaBoost通过向错误分类的数据点添加惩罚值来识别模型错误。而梯度Boosting使用梯度下降来校正模型权重。
关于AdaBoost和梯度Boosting之间差异的另一个次要点是损失函数。AdaBoost最小化指数损失函数,而梯度Boosting可以使用任何可微分的损失函数。指数损失函数容易受到离群值的影响;因此,梯度Boosting是处理噪声数据的理想Boosting算法。

虽然梯度Boosting是一种强大的方法,但其原始实现并未针对实际应用进行优化。因此,创建了eXtreme Gradient Boosting (XGBoost),使梯度Boosting适用于各种问题。
XGBoost只是对梯度Boosting进行了多项改进,使其运行更快、更准确。
以下列出了其中一些改进,包括
XGBoost是一种强大的开箱即用算法,可用于解决许多复杂的数据科学问题。

