

当你看到“监督学习”这个术语时,你会想到什么?同样的逻辑也适用于此。在监督学习中,当机器学习时,会有一个监督者。
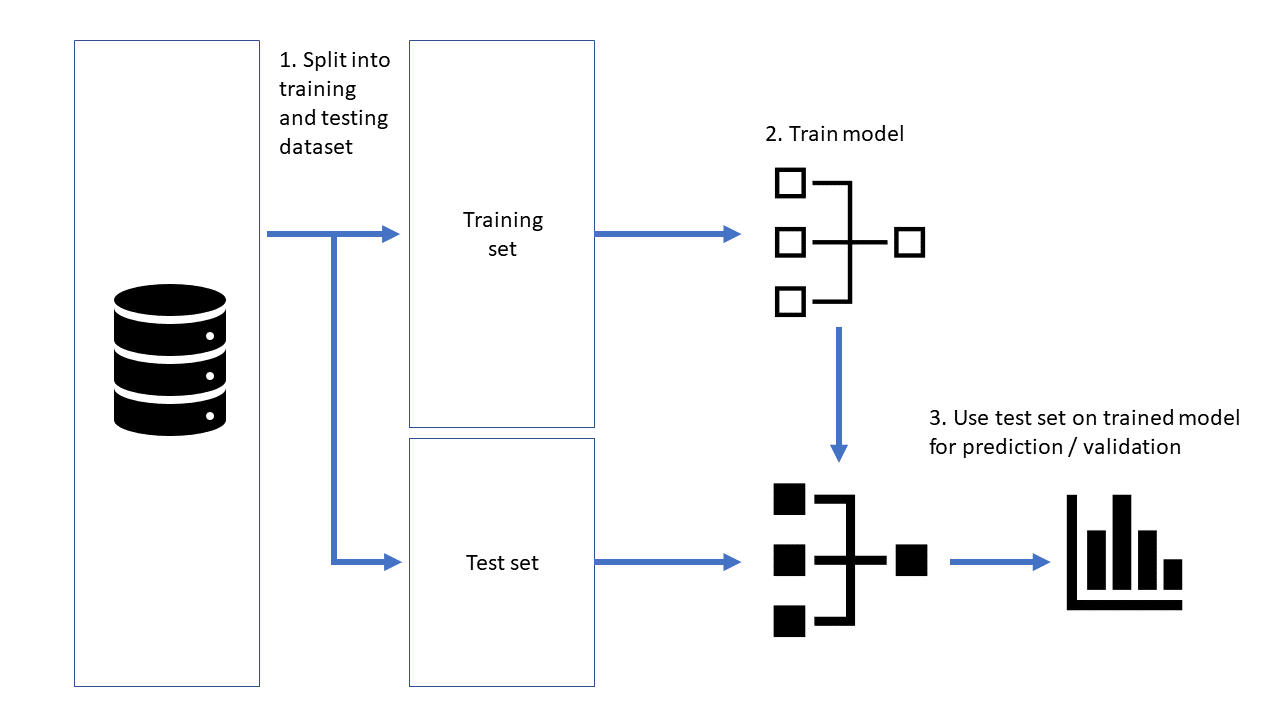
监督学习意味着我们必须提供一个称为训练数据的样本数据来训练机器。这些训练数据包含正确答案。训练机器后,我们提供需要测试的新数据。机器将使用我们之前提供的训练数据检查新数据并预测输出。
为了更好地理解,考虑一个例子,我们有一篮子蔬菜,需要对其进行分类。
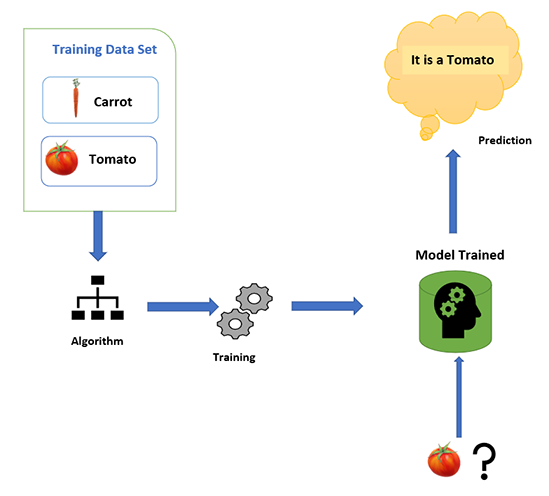
首先,我们从篮子中取出样本蔬菜。
假设我们拿了一根胡萝卜,我们把胡萝卜的特征,比如长、前端逐渐变细、橙色,输入给机器。
接下来,我们拿一个西红柿,然后把它输入给机器,例如它呈红色、果肉饱满、圆形。
然后我们把蔬菜提供给机器,机器借助我们输入给机器的细节正确识别出胡萝卜和西红柿。
我们首先输入给机器的细节称为训练数据,这个过程称为训练机器。然后我们给出的输入数据称为测试数据,机器根据监督学习做出预测。
在监督学习中,我们提供输入和输出,机器旨在找到一些映射关系来将输入变量与输出进行映射。
在我们的世界中,监督学习应用于各种领域,如欺诈检测、电子邮件过滤、图像分类等。
正如我们所知,监督学习涉及使用一些称为训练数据的样本数据来训练模型。在此训练中,模型将学习数据集中的数据,并且它们可以分析和预测我们将提供的新数据的输出。
假设我们有一些形状和颜色不同的物体。
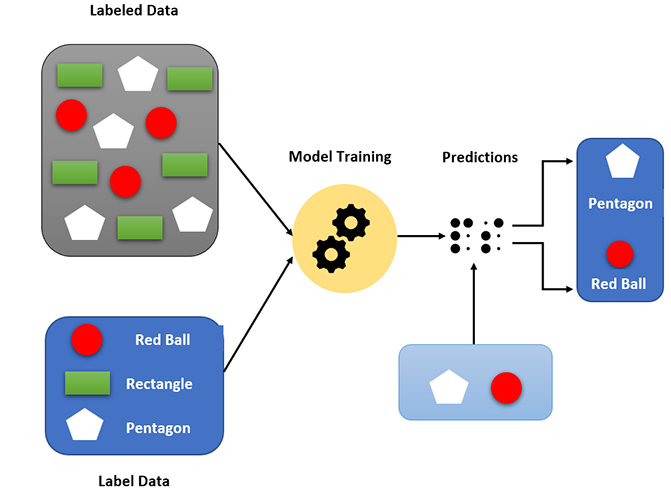
首先,我们必须从数据集中制作样本数据(称为训练数据)来训练模型。在我们的例子中,我们将圆形、矩形和五边形的物体提取到训练数据中
然后我们根据数据训练模型,如下所示:
现在模型使用训练数据进行训练,然后我们将新数据(新物体)提供给模型,以便模型可以根据训练数据(颜色和边数)轻松地对它们进行分类并预测输出。
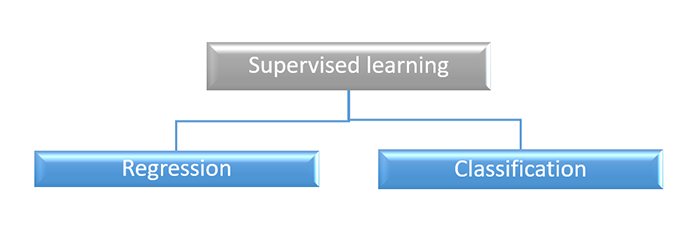
监督式机器学习算法可以根据我们必须使用算法完成的任务进一步分为两类。它们是:
回归算法用于天气预报、股票预测等,因为回归算法需要输入和输出变量之间的关系。在回归中,输出必须是一个实数值,并且它只使用训练数据预测单个输出。
例如,如果你想预测股票价值,输入将是许多因素,如公司数据、业绩等,但输出将是股票金额的一些实际单值。
在回归下有许多算法。其中一些是:
顾名思义,该算法用于将给定数据集分类或归类为不同的类别。这意味着当输出包含一些分类数据时,它被使用。
如果数据只分为两种类型,例如,分类为男性和女性、真或假、动物或鸟类,则称为二元分类。
如果它分为两个以上的类别,则为多类别。例如,我们必须将水果分为不同的类别。在分类下有许多算法,它们是:

