

在现实世界的数据中,有些数据点看起来与其他数据点“不同”。**异常值**是错误的数据点——它们是不代表数据的异常。简单来说,我们可以将异常值定义为数据点中的“异类”。它显示出与大多数数据不同的特征。

异常值是由于执行错误、不正确的输入、观测中的错误报告、抽样误差等原因形成的,它使我们偏离了其他数据点。
如果可能,我们必须删除异常值数据以减少错误并提高数据集的准确性,但这并非易事。为此,我们必须分析异常值数据,这通常被称为异常值挖掘或异常值分析。数据科学家在处理异常值之前会检查异常值对数据处理的影响。
并非所有奇怪的数据点都是异常值。如果数据点是极端的,但描述了潜在的自然现象,那么它们可能具有高杠杆作用。
作为数据科学家,区分异常值和具有高杠杆作用的数据点至关重要。我们将介绍一些简单的启发式策略来识别异常值。
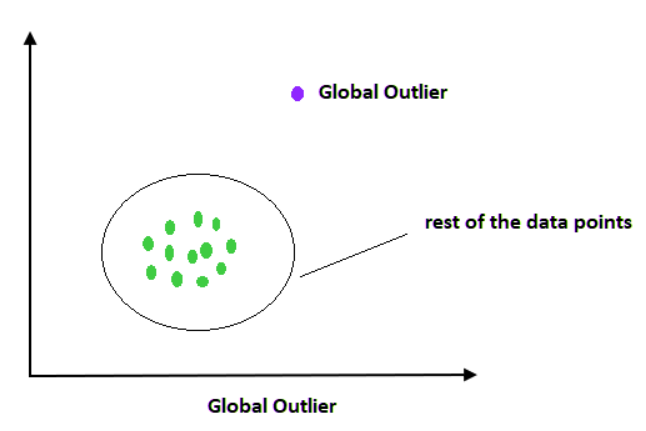
如果异常值数据与包含该异常值的整个数据集中的其余数据差异很大,则称为全局异常值。例如,考虑办公室中一些员工的年龄,如果你发现一个年龄为1000的员工,这将被视为全局或点异常值数据。
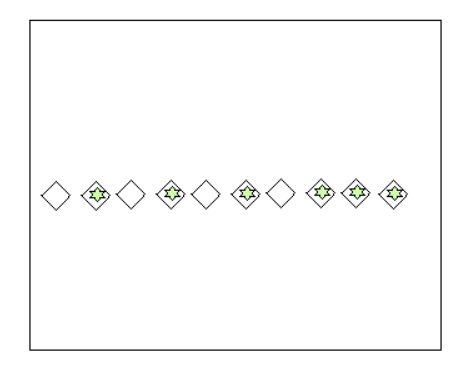
在某个上下文中,数据点值与该上下文数据集的正常数据点存在较大差异时,称为上下文异常值,这意味着当上下文数据集改变时,该数据可能不再是异常值。
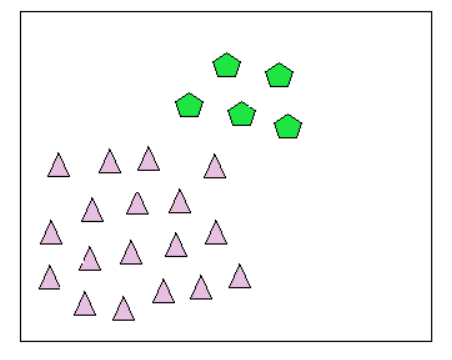
顾名思义,我们有一些数据点存在偏差或异常,但我们有很多彼此接近且具有相同或相似异常的数据点,这可以称为集体异常值。
机器学习算法使用数据集中的训练数据来训练模型。如果数据集中或训练数据中存在异常值,将导致训练受损,并产生高度不准确的预测和较低的效率。此外,在某些情况下,如垃圾邮件或欺诈检测,我们需要分析错误或异常数据以了解它们并加以预防。
我们有许多检测异常值的方法,它们大致分为两种类型:
在处理异常值时,一些数据科学家完全删除异常值并处理数据集。在另一种情况下,他们只控制异常值的数量。
现在我们必须检查一种方法以及它是如何处理异常值的。考虑K聚类方法,它将数据点作为一些具有平均值的簇。平均值接近的数据点被认为属于该簇。
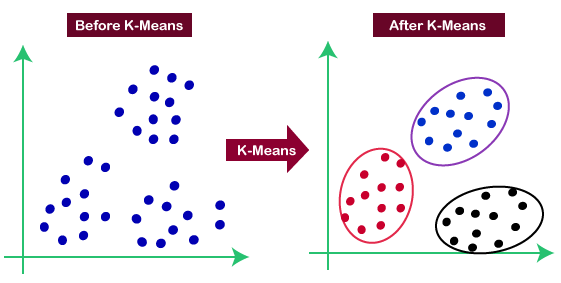
在这种寻找异常值的方法中,我们使用两件事。首先,我们必须设置一个阈值,使得如果一个数据点与最近簇的距离大于该阈值,则被视为异常值。
其次,我们必须计算测试数据和聚类均值之间的阈值距离。然后,如果测试数据和最近聚类之间的距离大于阈值,我们将测试数据视为异常值。
具有大残差的数据点往往会使回归系数偏离一般数据趋势。库克距离是一种评估删除某个数据点影响的指标,用于衡量数据点的影响力。
Python中的Yellowbrick库提供了计算库克距离的实现。文档可以在这里找到。
异常值往往会改变最小二乘拟合,并且其影响比我们根据其余数据预期的要大。
稳健回归试图降低这些异常值的影响。这导致残差显著,并且可以容易地识别出潜在的异常值数据点。
statsmodels库有一个稳健线性模型方法。文档可以在这里找到。
我们必须检查异常值对数据集的影响,主要考虑两点。
现在我们考虑一些预防异常值的技巧

