

数据可视化是创建数据视觉表示的过程。其核心在于,**数据可视化**使我们能够可视化数据并传达洞察。这是数据科学的关键部分,为了清晰地理解数据,我们使用图表、绘图和其他图像表示来表示数据,在数值数据的情况下,我们使用点、条形或线条。
众所周知,图形表示非常容易理解数据,并且有助于发现数据中的错误,例如异常值等。使用图表或其他图像表示,我们可以表示大量数据并使其易于理解。它允许关键人员做出数据驱动的决策。
数据专家使用探索性数据分析来分析和了解数据集的详细信息以及它们之间的关系和特征。
在机器学习工作流的数据分析阶段,数据科学家首先尝试理解并理清数据。这个过程称为**探索性数据分析 (EDA)**。
EDA 对于理解数据的底层结构至关重要。它有助于理解数据集变量之间的关系。探索性数据分析是数据科学家广泛使用的方法。借助 EDA,我们可以比传统方法更深入地理解数据。在 EDA 过程中,我们首先使用图表来检查数据。
在 EDA 过程中,我们还可以检查我们对数据所做的基本假设。通过可视化数据分布,我们可以了解哪些统计技术和机器学习模型适合给定的分析。
有不同的图表用于数据可视化,我们需要了解其中一些以便进一步,包括:
**散点图**使用沿水平轴(x轴)和垂直轴(y轴)映射的点来显示两个变量之间的关系。每个点代表一个与每个特征相关的独立数据点。如果点以特定顺序呈现趋势,则数据之间存在某种关系。如果散点图完全分散,那么我们可以预期数据变量之间没有关系。
我们将可视化鸢尾花数据集,这是一个经典的数据集,包含三种鸢尾花的花萼和花瓣的长度和宽度的测量值。
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Load Iris dataset
iris = load_iris()
为了简化数据可视化方法,我们将创建一个 Pandas 数据框。
# Load the feature data and the label-encoded target variable.
df = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
columns= iris['feature_names'] + ['target'])
# Concatenate the Iris species names.
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
print(df.head(10))
sepal length (cm) sepal width (cm) ... target species 0 5.1 3.5 ... 0.0 setosa 1 4.9 3.0 ... 0.0 setosa 2 4.7 3.2 ... 0.0 setosa 3 4.6 3.1 ... 0.0 setosa 4 5.0 3.6 ... 0.0 setosa 5 5.4 3.9 ... 0.0 setosa 6 4.6 3.4 ... 0.0 setosa 7 5.0 3.4 ... 0.0 setosa 8 4.4 2.9 ... 0.0 setosa 9 4.9 3.1 ... 0.0 setosa [10 rows x 6 columns]
现在我们将获取花萼长度和花萼宽度数据,并绘制两者之间的关系。
# Grab data
features = df[iris.feature_names]
# Make scatterplot and labels
plt.figure(figsize=(4, 3), dpi=200)
plt.scatter(x=features[iris.feature_names[0]], # Sepal length
y=features[iris.feature_names[1]], # Sepal width
c=iris.target, # Iris species type
cmap='viridis') # Color for each Iris species
plt.title("Sepal length v. sepal width")
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])
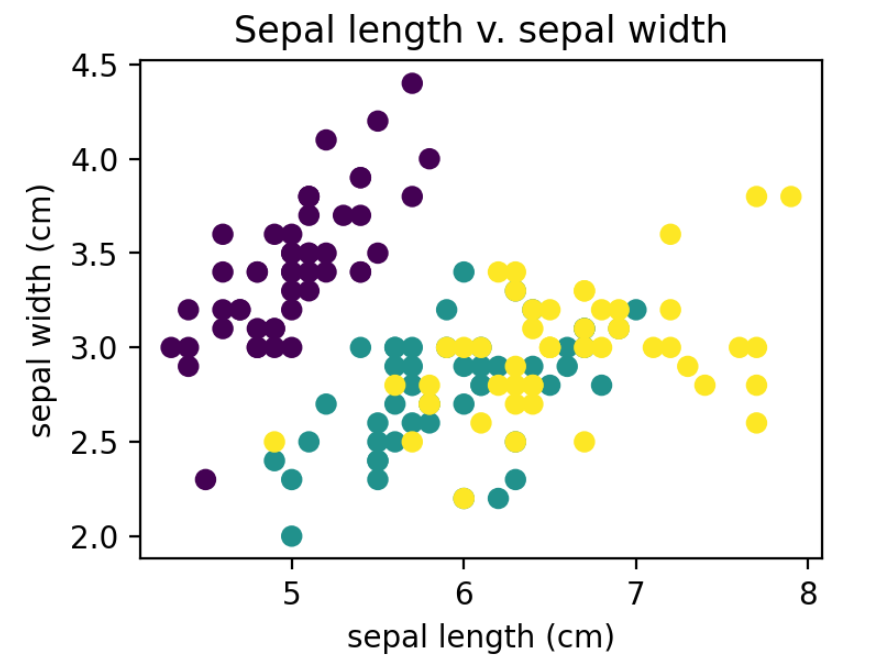
图示为花萼长度和花萼宽度之间的关系。每个点的颜色对应于不同的鸢尾花品种。从散点图我们可以得出结论:
• 花萼长度和宽度呈正相关,并且
• 与紫色对应的物种与其他物种高度可分离,可能表明其独特性。
散点图在特征超过 3 个时解释起来要困难得多,这限制了它们在小型和低维数据集中的使用。
**条形图**显示**分类**数据与每个类别相关的**数值**数据之间的关系。数值数据可以表示任何东西,从计数到基本指标(例如,平均值、中位数、众数)。
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
# Load Iris dataset
iris = load_iris()
# Grab data
features = df[iris.feature_names]
# Make barplots by Iris species
plt.figure(figsize=(3, 2), dpi=200)
sns.countplot('species', data=df)
# Plot attributes
plt.title("Iris species counts")
plt.xlabel("Iris species")
plt.ylabel("Frequency")
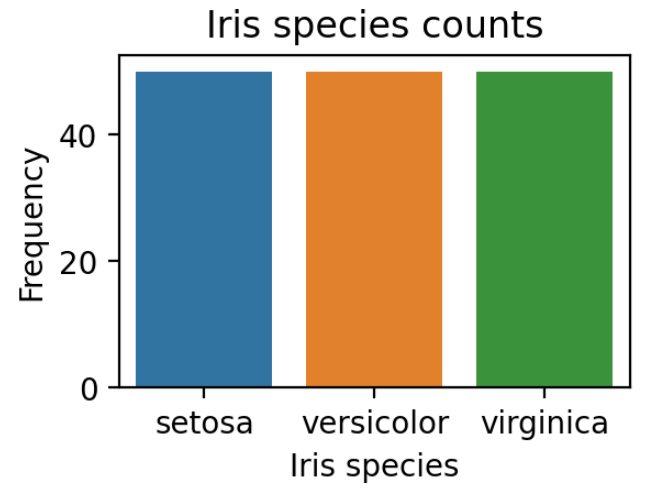
条形图显示数据集均衡良好。数据集中有相等数量的鸢尾花物种。这在分类问题中很重要——数据集越不平衡,预测其他类别就越困难。
**直方图**类似于条形图,但它用于检查频率而不是趋势。直方图揭示了连续数据的底层数据分布。一个轴显示数据值,而另一个轴显示给定区间或**bin**内数据点的频率。
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Load Iris dataset
iris = load_iris()
# Load the feature data and the label-encoded target variable.
df = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
columns= iris['feature_names'] + ['target'])
# Concatenate the Iris species names.
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
print(df.head(10))
# Grab data
features = df[iris.feature_names]
# Make histogram and by features
features.hist(figsize=(10, 10))
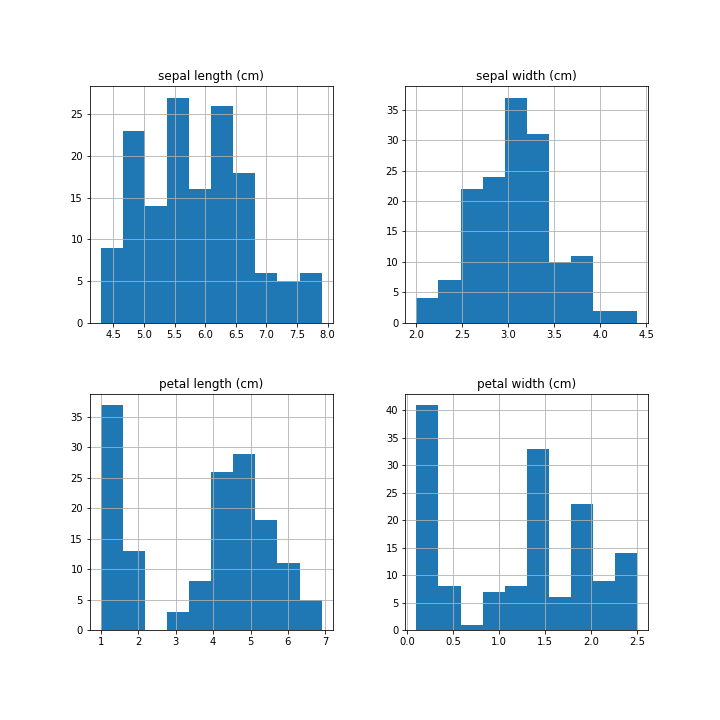
这些直方图显示每个特征都有不同的分布。数据的这种差异允许机器学习模型对数据进行分类。
**热力图**本质上是一个颜色编码的矩阵。这意味着矩阵的每个单元格根据该变量的值或风险从绿色到红色着色。我们都知道绿色是健康的单元格,当它向红色移动时风险会增加。它比数字更容易理解。
热力图帮助我们可视化可能具有多个特征的多元数据集。它们创建了任意两对特征和/或观测值之间关系的视觉地图。这些值可以是原始数据点或一些聚合指标。
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
# Load Iris dataset
iris = load_iris()
# Load the feature data and the label-encoded target variable.
df = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
columns= iris['feature_names'] + ['target'])
# Concatenate the Iris species names.
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
print(df.head(10))
# Make Heatmap
plt.figure(figsize=(4, 2), dpi=200)
ax = sns.heatmap(data=features.T)
# Heatmap attributes
ax.set(xticklabels=[])
plt.axvline(x=50, c='black')
plt.axvline(x=100, c='black')
plt.title("Iris data heatmap")
plt.xlabel("Individual data points")
plt.ylabel("Features")
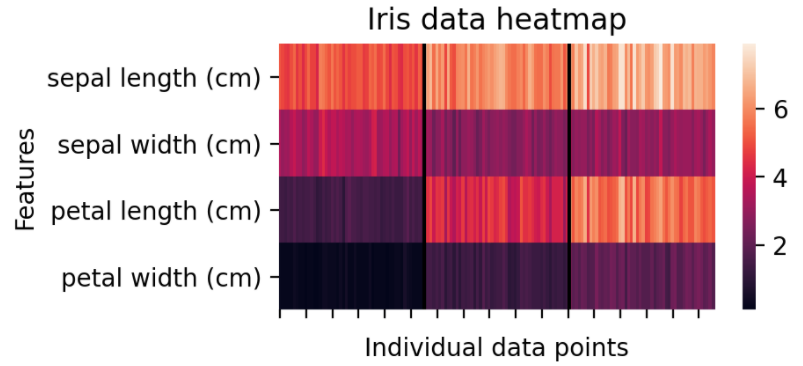
此热力图显示原始数据值。黑线突出了三种不同鸢尾花物种和单个特征值之间的分离。
**箱线图**是可视化数据和与数据相关的一些有用摘要统计信息的简洁方法。
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
# Load Iris dataset
iris = load_iris()
# Load the feature data and the label-encoded target variable.
df = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
columns= iris['feature_names'] + ['target'])
# Concatenate the Iris species names.
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
print(df.head(10))
# Make boxplot
plt.figure(figsize=(7.5, 5))
plt.boxplot(x=features.T, labels=iris.feature_names)
# Plot Attributes
plt.xlabel("Features")
plt.ylabel("Measurements (cm)")
plt.title("Iris data distribution")
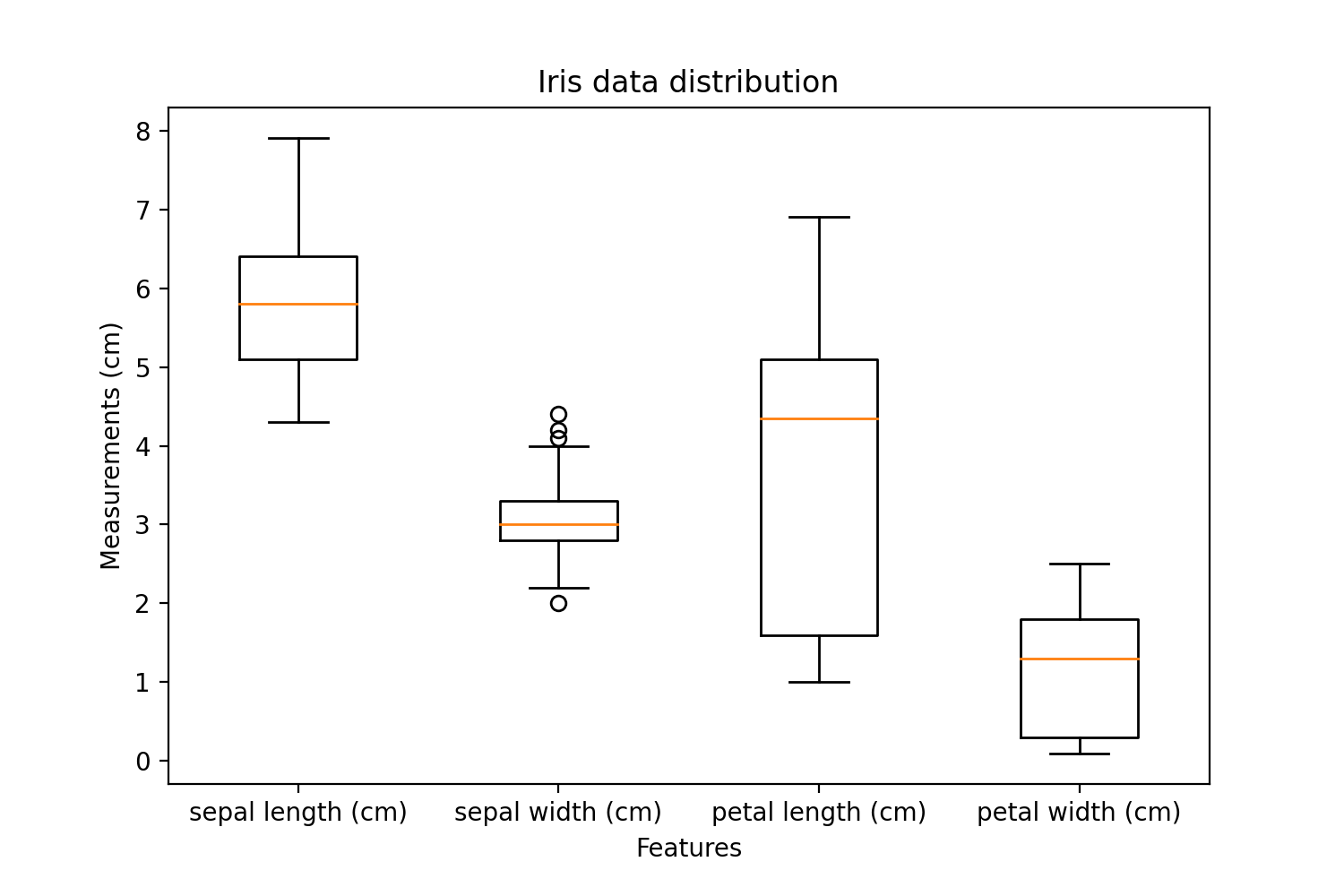
橙色线代表中位数。整个盒子显示了在上四分位数和下四分位数内可接受的值的分布——基本上是 50% 的数据。晶须代表数据的前 25% 和后 25%,不包括晶须顶部和底部的离群点。晶须可以定义为从盒子延伸到最大值和最小值的垂直线。
花萼宽度中的一些数据点被分类为超出四分位数的异常值。这表明花萼宽度包含一些噪声数据。有趣的是,花瓣长度的值分布与其他特征相比高度多变。这表明它可能不是区分鸢尾花类别的有用特征。
数据可视化是数据的图形表示,探索性数据分析被数据科学家用来借助数据可视化来分析和学习数据之间的关系。
我们使用不同的方法以图形方式可视化数据,包括散点图、条形图、直方图、热力图和箱线图。所有这些方法都表示数据变量以及它们之间的一些关系、风险、频率或统计数据。

