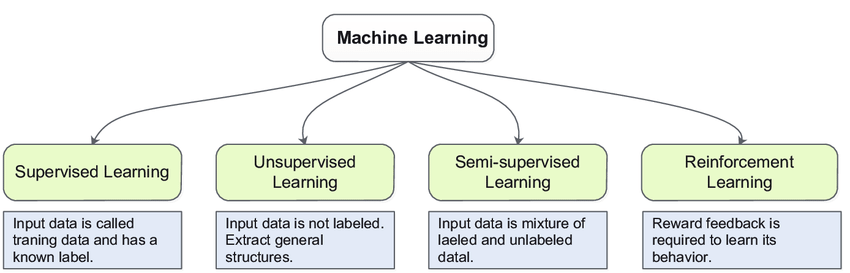
机器学习是一个帮助计算机从数据中学习的过程,这将有助于机器自己做出决策,也就是说,机器学习有助于人工智能(AI)的发展。
每种机器学习算法解决不同类型的问题。我们必须根据我们期望的结果和我们提供的数据来选择机器学习模型。在本机器学习教程中,我们将涵盖所有机器学习模型。
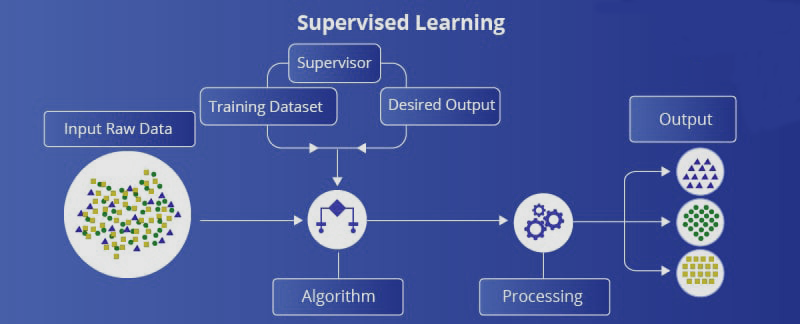
监督学习是一种机器学习,我们向机器学习系统提供样本训练数据来训练它。机器学习系统将根据我们提供的样本数据预测输出。
比如说,我们想根据往年的房价来预测下个月的房价。这是监督学习的一个例子。我们试图学习一个将输入数据集与结果相关联的函数或模型。
在这里,系统使用样本数据创建一个模型来理解和学习数据和数据集,并由此提供一个结果。
监督学习是在监督下完成的,这类似于教室里学生在监督员的指导下进行活动。监督学习的例子有垃圾邮件过滤器、房价预测、人脸识别等。
监督学习执行两种任务:
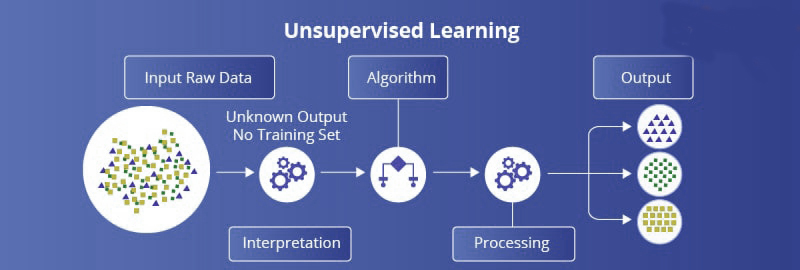
无监督学习与监督学习正好相反,这意味着机器学习是在没有任何监督的情况下完成的。它查看一个数据集,并试图找到数据的最佳底层表示。
没有标签或数值可供预测。相反,该算法学习数据分布以揭示数据集内的结构。分析师(您)必须解释这些结构并将其与某种意义联系起来。
在无监督学习中,我们提供没有任何关系的数据,算法在没有任何监督的情况下处理数据以从中找到一些相关的模式。在这里,算法必须从大量原始数据中找出关系。
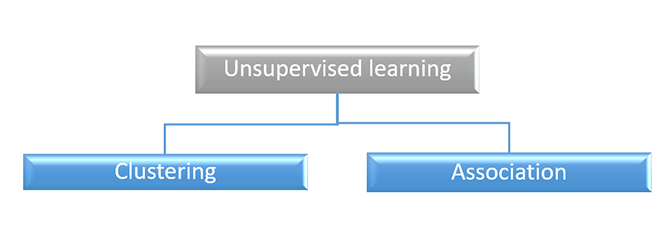
无监督学习进一步分为两种
无监督学习执行以下任务
在上述两种算法中,要么我们提供所有已标记的数据,模型使用这些已标记的数据并预测输出;要么根本没有已标记的数据,模型必须从数据中找到关系和模式。
半监督学习介于两者之间,这意味着我们有一些已标记的数据,但由于成本高昂,无法为整个数据集提供已标记的数据。
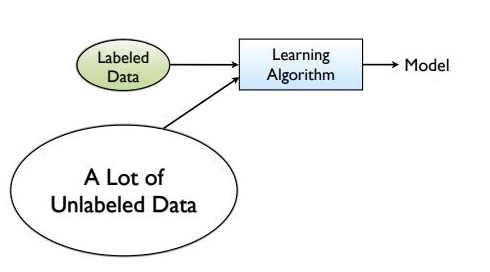
在现实世界的应用中,我们有大量的输入数据,但标记的数据非常少。半监督学习试图利用无监督学习和监督学习的优点。
在半监督学习中,无监督学习将未标记的数据分组到聚类中。然后用户可以标记这些聚类,并将数据输入到监督学习算法中。
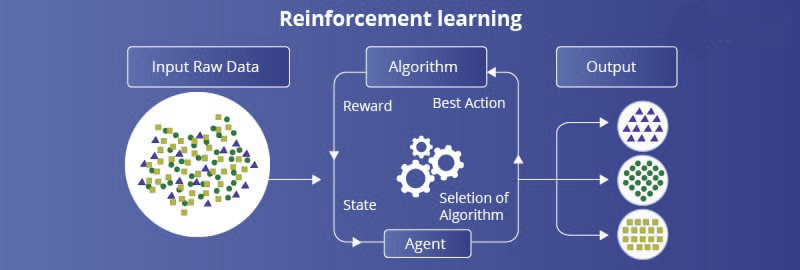
强化学习是教导算法做出决策的过程。它是一个基于反馈的系统。用户为给定任务中的正确和错误决策提供奖励和惩罚。强化学习算法试图获得更多的奖励以实现更高的准确性,并通过与环境互动来学习。
强化学习是我们与人工智能相关的另一项新兴技术。
算法的选择始于数据的数量以及数据集内的数据类型。如果目标是执行分类任务并对数据集中的数据进行分类,那么我们就不能使用像线性回归和LASSO这样的基于回归的算法。
机器学习从业者用来选择算法的另一个通用技巧是评估数据点的数量与我们正在考虑的变量数量。如果数据点数量少而变量数量多,基于线性的模型往往效果更好。然而,如果数据点很多而变量数量较少,非线性模型则更合适。
总的来说,现实世界的数据在一个数据集中往往有多种数据类型(例如,数值、分类等),并且通常是大的高维时序数据集。
总的来说,我们的目标是使用最合适的算法,该算法可以提供输入数据与某些结果之间关系的最佳模型,或者如何最好地将相似的数据点分组在一起。如果我们能用一条直线来做到这一点,线性算法往往表现良好。
然而,当数据没有这些线性关系或无法用直线分隔数据时,我们应该使用非线性算法。总的来说,现实世界的数据往往更具非线性。
如前所述,算法越非线性,其可解释性就越差。虽然非线性算法在处理非线性数据时往往表现得更好,但有时我们需要选择准确性较低但更易于解释的算法。
这一点在医疗保健行业尤为明显。识别错误来源对于临床医生相信模型试图预测的内容至关重要,因为临床医生可能要为医疗事故负责。因此,如果模型易于解释并且可以缓解痛点(例如,更高的准确性,更少的劳动等),它将被接受,而不是一个黑箱模型。
在生产级别部署机器学习算法时,训练时间至关重要。一般来说,训练时间越长,与模型相关的成本就越高。这些成本来自分配给模型训练的计算资源及其将模型推向市场的延迟。
一般来说,模型越简单,训练模型所需的时间就越快。然而,更复杂的模型往往更适用于现实世界的数据,因为它们具有非线性特性。因此,用户或公司必须决定哪种模型最合适,并理解成本和性能之间的权衡。
我们可以将算法分为6个通用的机器学习方法家族