

许多公司都对获取和分析更多数据感兴趣,无论是消费者行为数据、汽车摄像头数据还是用于新药的生物医学数据。专门围绕数据提出问题并使用数学模型回答这些问题的人是**数据科学家**。
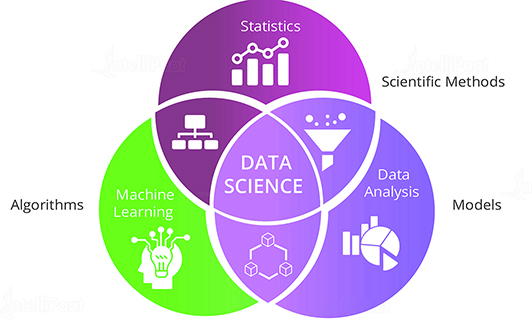
为什么**数据科学**现在如此热门?如果你拥有数据,你可以提取大量信息并做出更好的决策。这些决策可以提高业务效率,或者深入了解你肉眼无法看到的业务趋势。
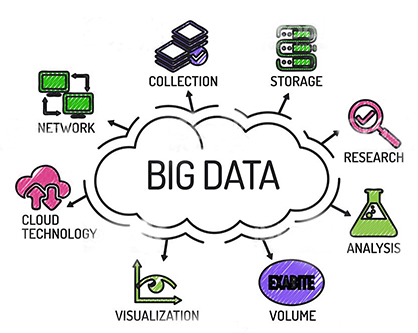
**数据**是一种将信息编码到机器上的方式。每当你用不同的类别、文本和数量制作 Excel 电子表格时,你就拥有了一个数据集。如果你有多个数据集,你可以将它们存储在一个称为**数据库**的容器中。
**大数据**随着我们继续在亚马逊上购物或使用 FitBit 记录心率而随着时间积累这些较小的数据集。这些数据集规模庞大,处理和存储大数据具有挑战性。然而,它们包含丰富的信息,机器学习算法可以利用这些信息来解决不同的问题。
机器学习是世界上发展最快的技术之一,它已经占据了世界上大多数顶级公司的一席之地。机器学习帮助计算机从数据和经验中学习,从而像人类一样自主决策。机器学习使用各种算法、数学统计和模型来从数据中学习并做出决策。
在我们的现代技术世界中,有许多应用程序使用机器学习,例如语音识别、语音识别、语音翻译、产品推荐、视频推荐、导航等等……
到目前为止,只有人类才能从经验和数据中学习,并能够根据数据和环境做出决策。我们拥有的计算机将根据我们的指令集工作。所有指令都硬编码到计算机中,称为程序,以确保其正常运行。
现在,如果计算机本身能够从数据和环境中学习,并能够根据数据做出决策呢?此外,如果计算机系统能够根据数据自行改进,那会怎么样?我们已经通过机器学习实现了这一点。
机器学习属于人工智能(AI)范畴。一台机器能够分析和学习所提供的数据,并根据数据做出决策或给出答案。
亚瑟·塞缪尔(Arthur Samuel)于1959年提出了机器学习一词。
通过使用来自大型数据集(称为训练数据)的样本数据,机器学习算法能够构建模型,这些模型有助于在无需编程的情况下提供决策。机器学习算法可以从数据中学习,并且它们可以自行改进以使其更准确和高效。
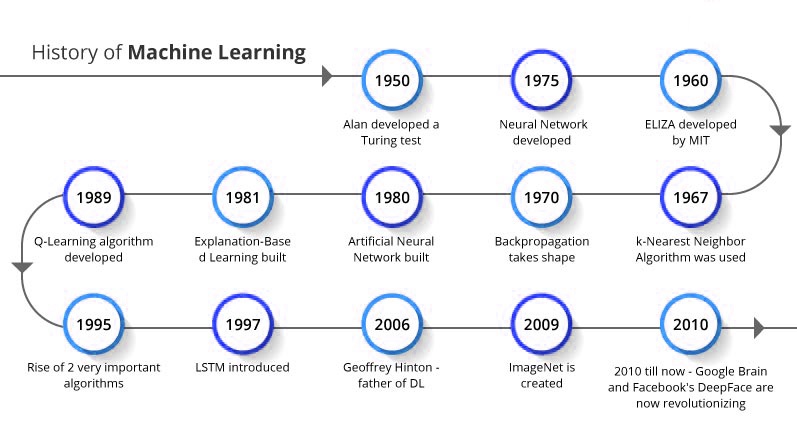
机器学习的历史始于1943年,当时沃尔特·皮茨(Walter Pitts)和沃伦·麦卡洛克(Warren McCulloch)提出了一本关于神经网络的书。1949年,唐纳德·赫布(Donald Hebb)出版了一本名为《行为的组织》(The Organization of Behavior)的书,其中包含了神经网络的关系,这是机器学习历史上的第二个里程碑。亚瑟·塞缪尔(Arthur Samuel)于1959年首次引入了机器学习概念。此后每年,机器学习领域都在发展,直到现在。目前,自动化机器学习的概念正在取得进展。
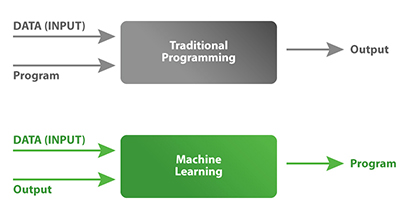
在编程中,我们需要一个程序员,他能够为正在开发的软件编写带有逻辑的指令(称为程序)来执行任务。这需要许多专家才能做到完美。
机器根据指令检查和分析数据以提供输出。数据中的任何微小变化都会导致机器失败,或者需要程序员修改指令,这需要大量时间和精力。
在机器学习的情况下,程序员的工作由机器本身完成。我们向机器提供输入数据和输出,机器分析并学习输入和输出之间的关系以生成指令。在机器学习中,由于机器会根据输入和输出数据生成指令,因此无需程序员对输入数据进行任何更改。
数据是我们现代科技世界中最有价值也是最主要的问题。海量数据及其分类和学习对于传统编程来说是非常困难的任务。这时机器学习的重要性就体现出来了,我们可以利用机器学习算法和模型自动从数据中学习,无需耗费太多精力和时间。
我们可以训练机器学习算法来创建模型,并借助这些模型预测所需的输出。它还可以利用数据来改进自身。我们将在接下来的教程中了解更多关于其需求的信息。
机器学习是人工智能(AI)中所有学习和决策发生的大脑。
对于人类来说,我们从经验中学习,经验越多,我们做出的决策就越准确。如果我们面临一个新情况,我们无法百分之百确定我们的决策会像熟悉的情况那样准确。
机器也遵循同样的逻辑,我们必须让机器从数据中学习以获得准确的输出。机器学习算法从数据中学习并建立模型,即使对于新数据也能预测输出。
机器学习的准确性取决于数据量、数据质量以及我们为数据选择的算法。我们稍后可以了解详细信息。
当机器学习遇到复杂问题时,它会从所有来源收集数据,并对数据进行预处理以消除错误。然后,我们制作一个名为训练数据的样本数据,将其输入到机器学习算法中。
该算法接受训练数据以创建一个模型,该模型能够预测输出。模型完成后,我们必须用新数据检查模型,以验证模型是否能准确预测输出。
使用机器学习,我们无需为新数据制作一套新的指令。
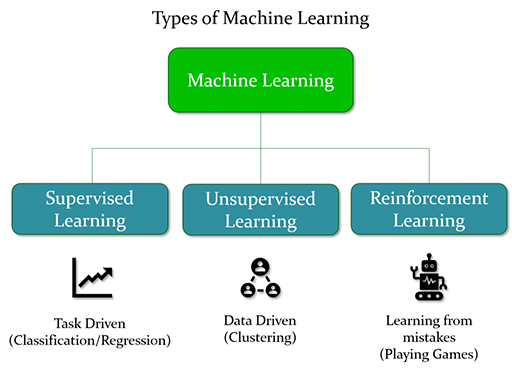
机器学习方法根据我们提供的数据质量和我们期望模型输出的结果可分为三种类型,它们是:
它们又进一步分为许多类别,我们将在接下来的教程中深入学习。

有几种编程语言可以让你使用机器学习库,这样你就不必自己编写算法。我们将简要介绍 3 种用于机器学习的常用语言。

**Python** 是一种开源通用编程语言,是当今数据科学社区的首选语言。这是因为:

**R** 编程语言不应被忽视。统计学家首先在 R 中开发前沿的统计和机器学习算法,然后再将其转换为其他语言。
虽然 R 的语法与 Python 相比有些笨拙,但它仍然具有许多相同的优点。如果您的项目需要使用最新的机器学习算法,请使用 R。

结构化查询语言(SQL)被认为是一种用于操作和从数据库中提取数据的语言。但您可以使用 SQL 直接或通过 Python/R 脚本运行机器学习算法。
这是业界实现机器学习的常见方式,也是您开发数据科学工具箱时需要掌握的重要语言。
以下是一些流行的众包数据科学家解决现实世界问题的网站:

