

在之前的教程中,我们学习了一种使用线性回归对变量进行建模的强大方法。然而,线性回归模型极易受到噪声的影响。本教程将介绍对数据集进行去噪和提高线性模型性能的策略。
当我们得到一个新数据集时,我们可能会发现在探索性数据分析过程中存在高度相互关联的特征。此外,我们可能还会发现无信息特征无法将两个类别相互分离,或者识别出方差较低的特征。如果存在不重要的特征,它将对我们系统的准确性产生负面影响,增加模型的复杂性。
如果可能,我们应该摆脱这些特征。从数据集中移除冗余或无信息特征以构建良好系统的过程被称为特征选择。特征选择的优点在于:
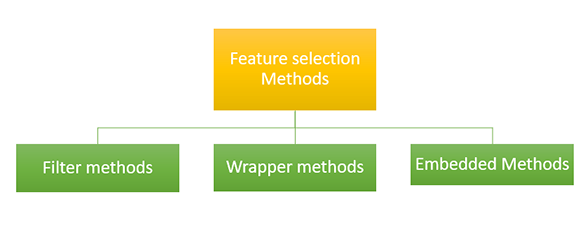
有几种执行特征选择的策略,它们是:
过滤方法可以在不考虑机器学习算法的情况下选择特征。过滤在机器学习实现中的预处理步骤中完成。过滤方法是一种有效且廉价的方法,可以移除重复、相关和冗余数据。过滤方法在处理多重共线性数据方面效果不佳,因为在过滤方法中,选择是针对每个数据独立进行的,如果输入数据相互关联,则会很困难。

过滤使用这些技术:
信息增益可以定义为特征为目标预测提供多少信息以及减少预测中的错误。每个输入属性的信息增益取决于目标值。
此检验用于分类值,通过比较观测值与期望值来找出值之间的关系。
在此方法中,我们使用Fisher准则为每个属性打分。然后选择Fisher值较大的属性,这些属性必然是最佳选择的特征。最终,我们得到一组良好的特征。
在此方法中,我们移除方差不满足某个阈值值的输入特征。我们假设高方差值表示输入特征包含更具生产力的信息。
在此方法中,我们使用平均值,然后计算与平均值的差值。该过程类似于方差阈值方法,但使用平均值及其差值。
当两个输入变量相互依赖时,使用此方法。在这种情况下,我们观察通过使用另一个变量可以收集多少一个变量的信息。它衡量一个特征对预测输出的贡献程度。
在此方法中,我们测量从数据集中随机选择的属性的质量。
我们将描述封装方法——这些方法试图在数据子集上训练模型。根据模型的性能,我们决定添加或删除特征,然后查看新模型是否优于旧模型。
封装方法的主要优点是它们能够为训练算法提供最佳特征集。它能提供更高的准确性和效率,但代价是需要更多的计算能力。

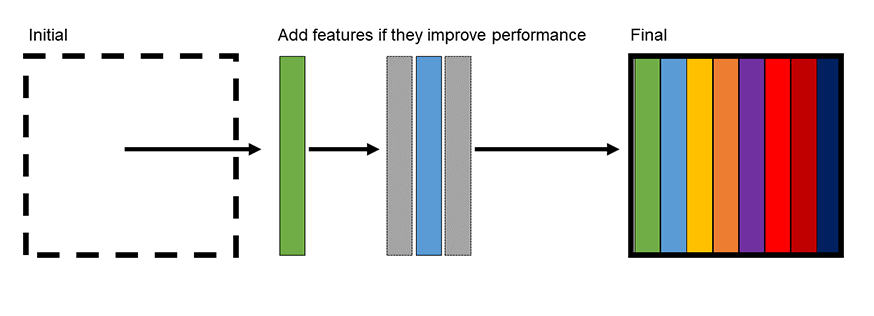
前向选择是我们从没有特征被建模开始。然后,我们迭代地向模型中添加一个特征,并查看该特征是否提高了模型性能。性能可以通过多种指标来衡量,包括均方误差或决定系数。
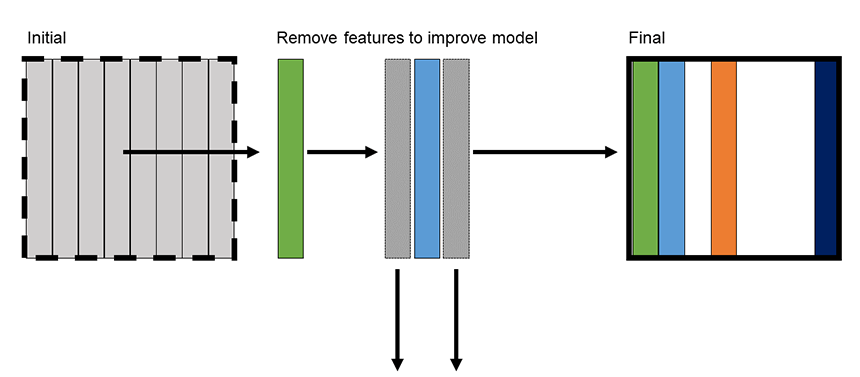
后向消除是我们从对数据集中所有特征进行建模开始。然后,我们迭代地移除对模型没有影响的特征,或者移除后能提高模型性能的特征。
前向选择是我们从没有特征被建模开始。然后,我们迭代地向模型中添加一个特征,并查看该特征是否提高了模型性能。性能可以通过多种指标来衡量,包括均方误差或决定系数。
逐步回归结合了前向选择和后向消除的优点。通过结合这两种方法,我们消除了无信息特征,同时重新引入了可能过早被剔除的特征。
scikit-learn库有几种执行特征选择的方法,主要通过消除方法。特征选择的文档可以在这里找到。
在嵌入方法中,我们将特征选择算法作为机器学习算法的一部分使用,因此在此方法中,我们可以克服过滤方法和封装方法的缺点。通过这种方法,我们还可以将过滤方法的快速简便等优点与封装方法的准确性和效率等优点结合起来。
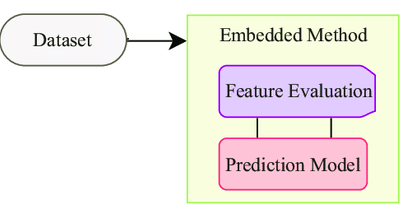
一些嵌入式技术有:
在此方法中,我们对输入变量使用惩罚以避免模型过拟合。我们已经知道我们在lasso中将这种正则化用作L1和L2正则化。在这里,我们为系数添加了一个惩罚,使其部分归零并从数据集中消除。
在这里,我们检查哪些因素对预测输出有影响,我们称之为特征重要性,我们在随机森林方法中使用此方法。我们使用特征重要性进行选择。

