

数据可以有各种形式,例如来自财务报表的数值数据,以及图像和音频片段。在所有这些情况下,数据都需要经过处理才能捕获数据中的重要信息。数据处理是一种将原始数据转换为有意义的数据,以便从数据中获取更多信息的方法。

数据处理任务可以使用机器学习算法和统计数据完全自动化。数据处理任务是一个结构化过程,按以下步骤完成:
这是数据处理的第一步,其主要任务是从所有可用和可靠的资源中收集数据。收集数据的主要标准是质量,收集到的数据质量必须良好且准确。这是数据处理中需要巨大精力和时间的任务。收集到的数据可能存在一些错误,包括:
有几种技术可以解决这个问题,包括:
在此步骤中,我们需要使数据准确,并且必须解决收集到的数据中的一些问题。最后,我们需要将数据转换为指定的格式,以便算法可以使用这些数据,其中包括:
我们从不同来源收集的数据可能具有不同的格式和文件格式,我们需要将这些数据转换为少量格式,以便机器学习算法能够更准确地使用数据。
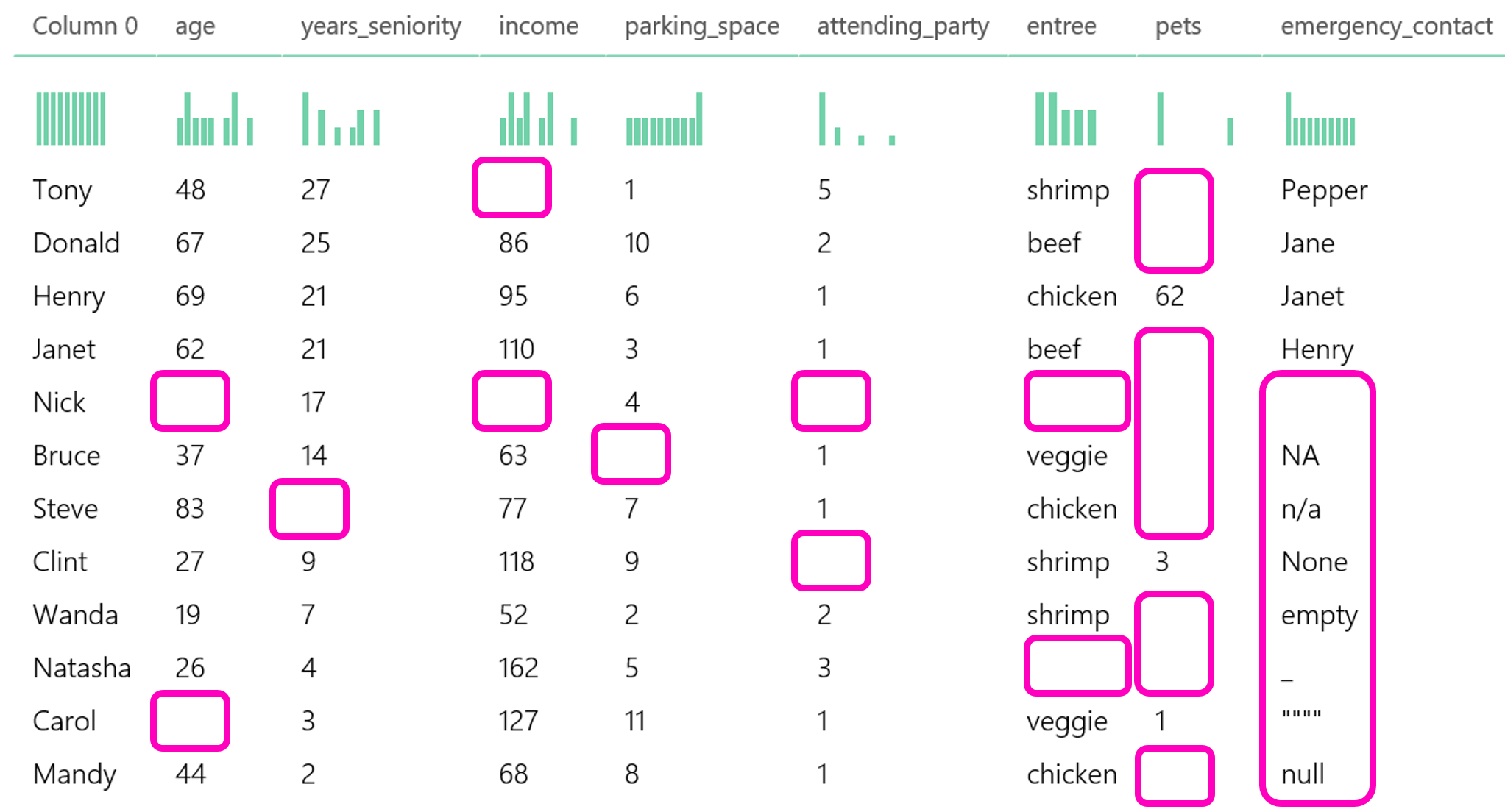
真实数据是混乱的。缺失信息是真实数据集的一部分。虽然没有完美的解决方案来解决这个问题,但有方法可以在不删除整个观测值的情况下使用带有缺失值的数据。
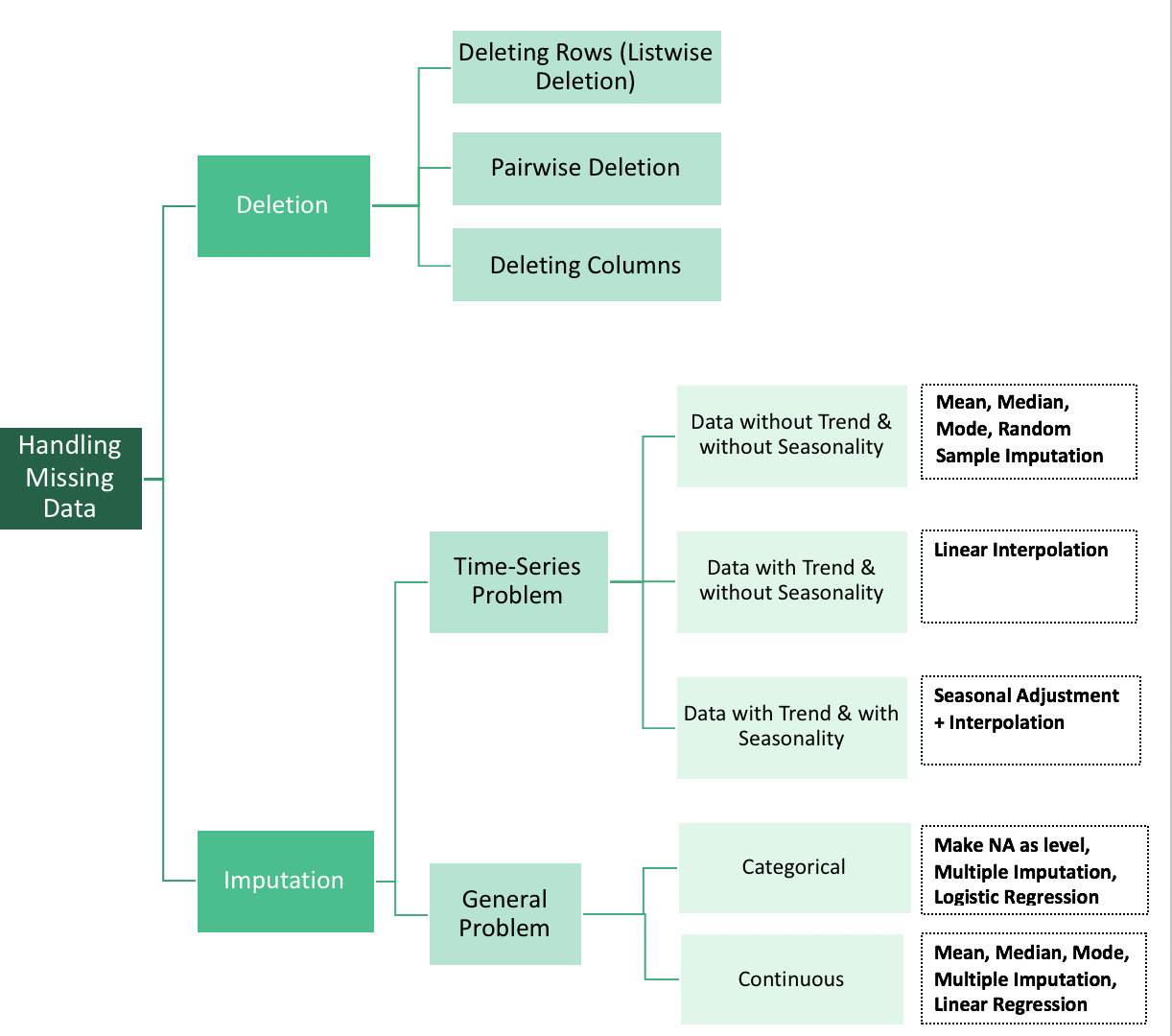
虽然这个解决方案并不完美,但如果你恰好知道单个观测值是随机丢失的,我们可以选择处理缺失值的算法。
一个例子是随机森林。它在大多数实现中会自动检测缺失值,并与它们一起工作以获得一个相当不错的模型。
删除数据,无论是按行(样本)还是按列(按特征),是处理缺失数据的另一种方式。这在以下情况下特别有用:
A. 特定数据点获取不可靠(按行删除)或
B. 如果大多数特征未被测量(按列删除)。
必须采取预防措施,以确保我们没有偏置数据集,并且我们有足够的数据。这两个问题都会影响模型性能。
最后,我们可以根据某种系统方法来填补数据。当我们的数据集很小,无法删除数据,并且不能简单地忽略缺失值时,这是一种理想的方法。
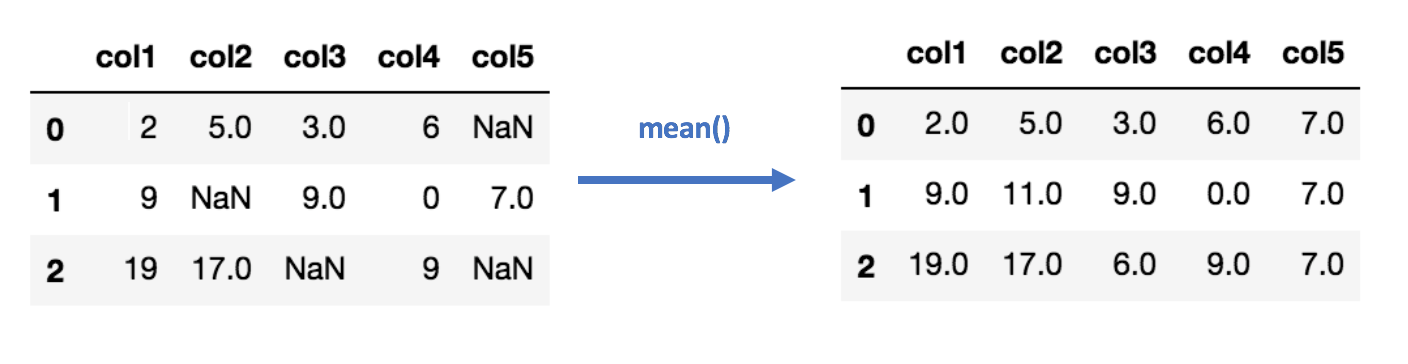
数据填补的常用方法包括使用数据的均值、中位数或众数填充缺失值。K近邻或线性回归也可以用于填补缺失值。在这两种情况下,我们都对数据做出了可能不成立的假设,并冒着使数据产生偏差的风险。
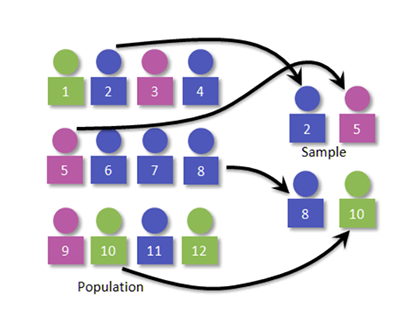
在某些情况下,由于数据中的错误,我们无法获取整个数据集。在这种情况下,我们可以从大量数据中抽取样本数据,这些样本数据可以用于训练机器学习模型。
抽样步骤
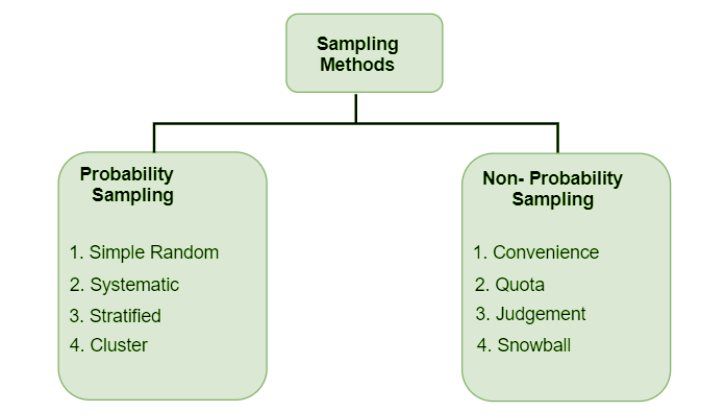
抽样方法类型
现在您已经为处理上传到库中的数据集选择了机器学习算法。现在我们必须看看处理过的数据的转换过程。许多转换方法包括。
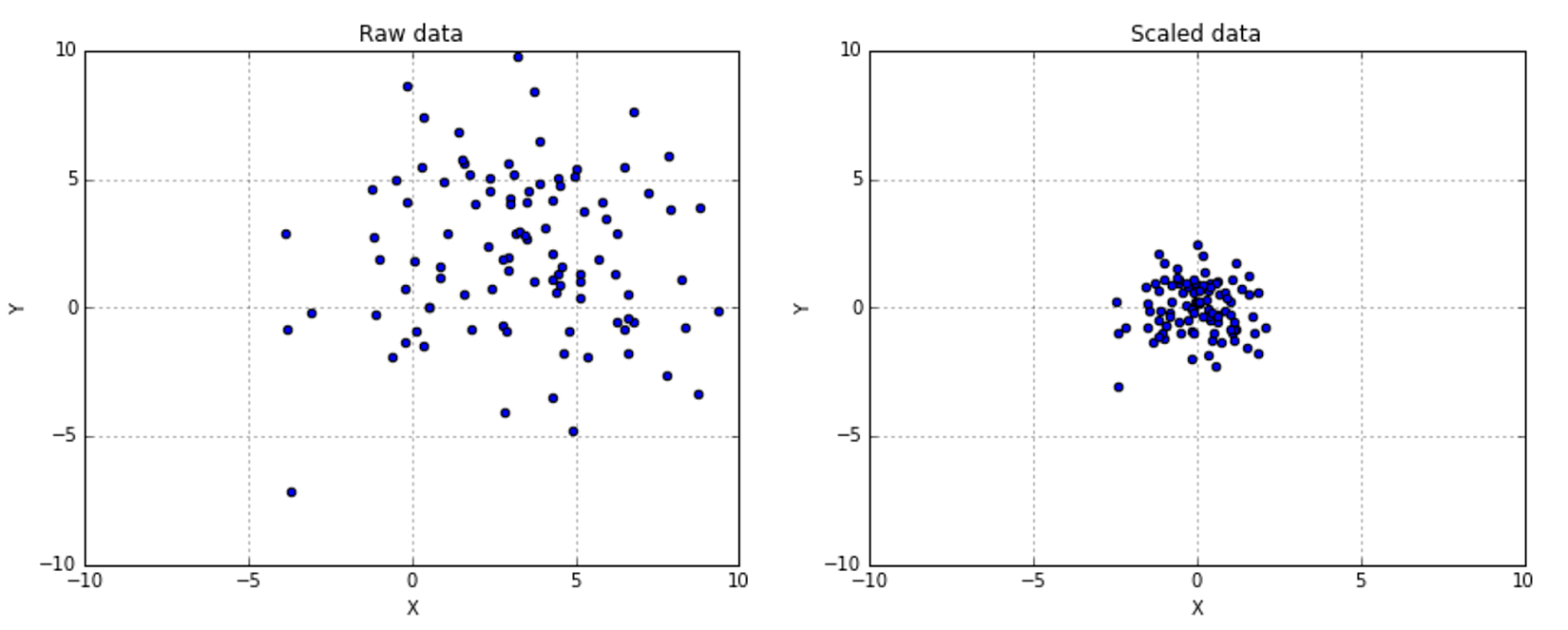
数据缩放是一种在不改变底层数据分布的情况下,标准化数据集中值范围的方法。
一种广泛应用的缩放方法是最小-最大缩放,我们将值转换为0到1的范围。
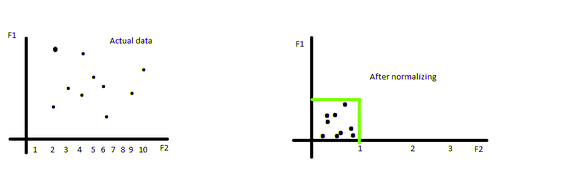
数据归一化改变底层数据分布,使其遵循正态分布。
一种常见的方法是计算Z-score。这种方法使用均值使数据居中,并将标准差设置为1。
在此过程中,我们使用分解算法将异构数据转换为三元模型数据。这里数据被分组为结构化、半结构化和非结构化数据。我们将为我们的机器学习算法选择其中一种。

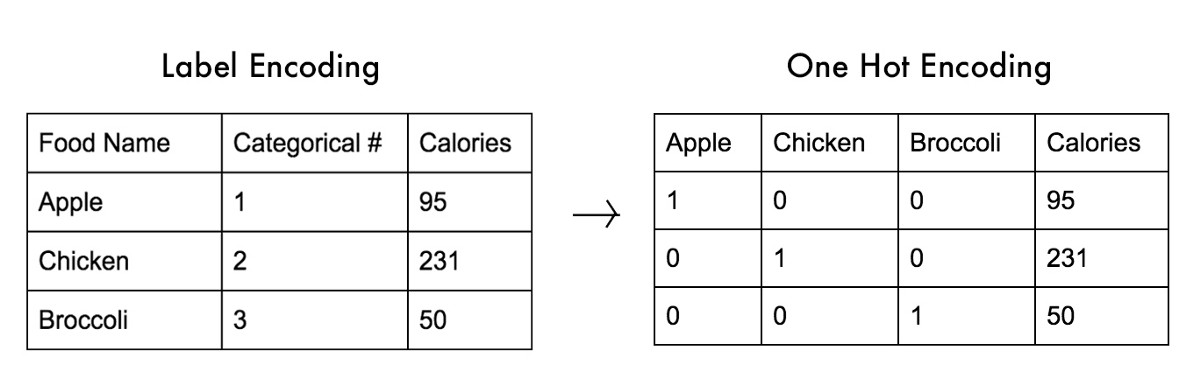
标签编码是将标签转换为分类算法可以使用的数字格式的过程。标签可以是分类数据或任何基于文本的数据。
传统的标签编码为每个类别分配一个唯一的值。虽然这是一种简单的方法,但模型可能会不恰当地权衡生成的数值。
一个解决方案是独热编码数据。我们为每个类别构建一个新列,如果它是一个特定类别,我们将其值设为1,否则设为0。这消除了将不同权重纳入算法的可能性。
在这里,我们将得到一些图形表示作为输出,例如图表、视频或图像等,这些都是有意义和有价值的,涉及以下步骤:
在此步骤中,我们将数据解码为可理解的格式,例如图表、视频或图像,用户可以随时访问这些数据,这些数据之前已编码用于机器学习算法。
这是数据处理的最后一步,我们将数据或输出存储在某些设备中以备将来使用。
数据处理是将原始数据转换为有意义的格式。这包括不同的步骤,即数据收集(我们从各种来源收集数据)。然后我们预处理数据以删除缺失数据并清除数据中的错误。然后我们转换数据以用于算法。第四步包括解码和接收输出,最后一步是保存该输出。

