

许多人认为机器学习仅仅是一种特定的算法,例如逻辑回归或随机森林。然而,在实践中,许多其他组件将决定模型的性能。这些步骤包括数据清洗和使用超参数调优来优化模型。
机器学习工作流程定义了机器学习项目必须遵循的步骤或路径,其中包括:
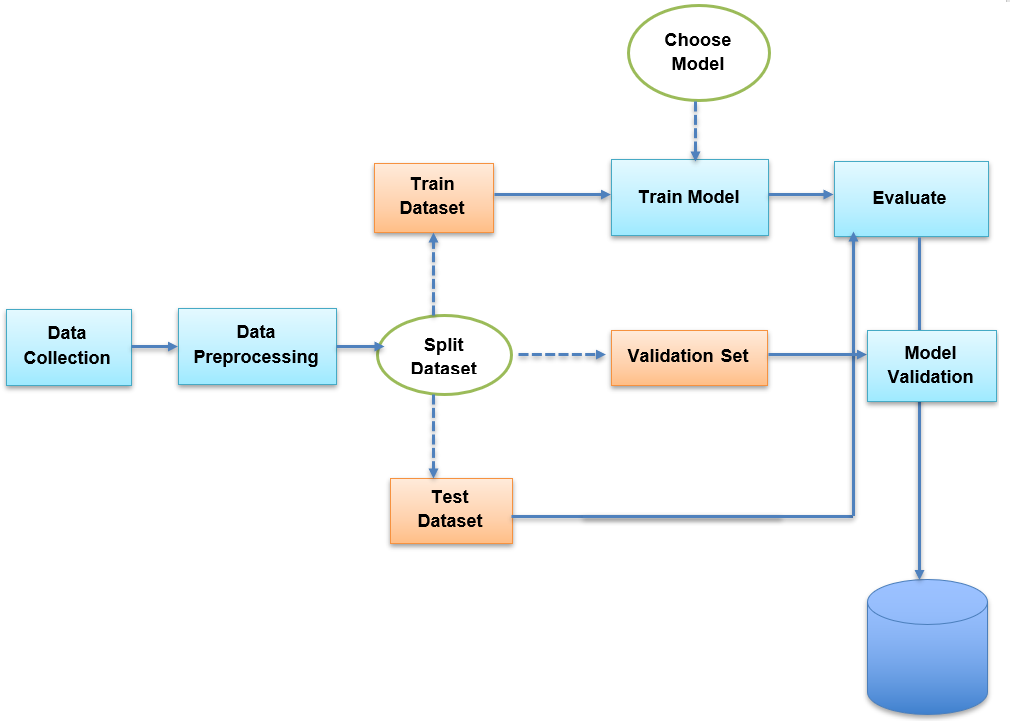
本教程将更详细地介绍机器学习工作流程的每个组成部分。
在此步骤中,我们必须从不同来源收集数据,这些来源可能是文件、数据库或传感器等。如果我们正在收集实时数据,我们可以直接使用物联网设备的数据。所接收数据的质量对于系统的准确性和结果非常重要。
我们从文件、扫描仪等收集的数据不能直接使用,因为它们会有很多不清晰、大值、错误和缺失数据。为此,我们必须进行数据准备。
希望有人已经生成了一个数据集,你可以用它来解决你的特定问题。否则,我们需要创建自己的数据集,将其输入到机器学习工作流程中。这可能是机器学习工作流程中最劳动密集、耗时和昂贵的部分。
一旦我们创建了数据集,我们需要创建一个数据存储,以便我们能够访问数据以进行后续步骤。重要的一点是,我们应该保留原始数据集的记录。这对于透明度和可复现性至关重要。
一旦我们加载数据,我们就应该“清理”数据。我们从外部世界获得的数据将包含:
这些数据不能直接应用于系统。我们必须使用不同的方法将原始数据清理成干净的数据集,这通常称为数据预处理。
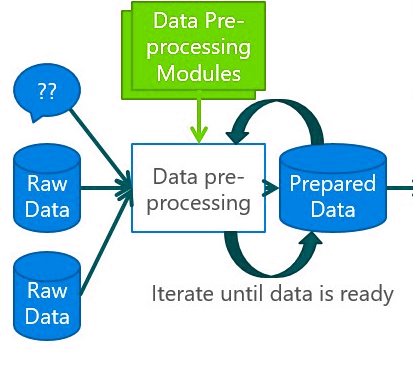
数据预处理通过不同的步骤完成,包括:
这是机器学习工作流程中复杂但必不可少的一步。如果不了解底层数据结构,我们可能无法理解模型输出。
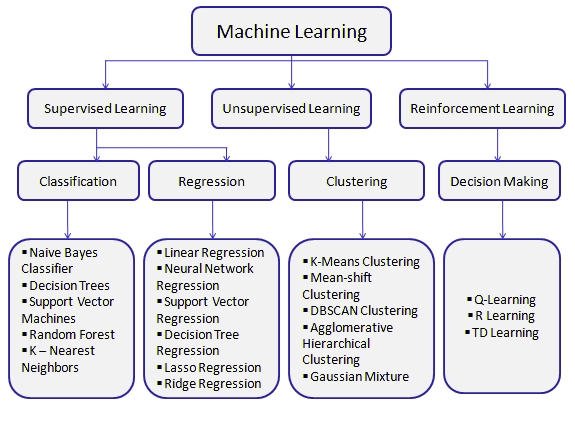
我们已经从之前的教程中了解到,我们有不同的模型,需要根据我们的目标类型和所提供的数据类型来选择最佳性能。
如果数据已标记且需要对数据进行分类,我们将使用分类算法。如果我们需要进行回归任务且提供的数据已标记,我们可以使用回归学习模型。如果数据未标记,我们可以使用聚类模型为给定数据创建聚类。
最后,一旦我们处理了数据,我们需要将其拆分成三个数据集,用于训练和评估我们正在训练阶段使用的机器学习模型,以提高模型的性能。为了进行训练,我们必须拆分数据集:
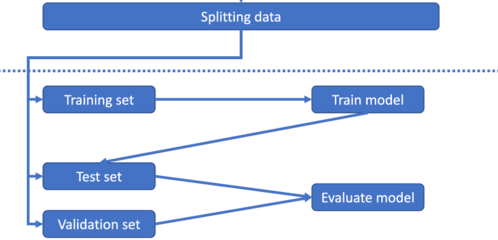
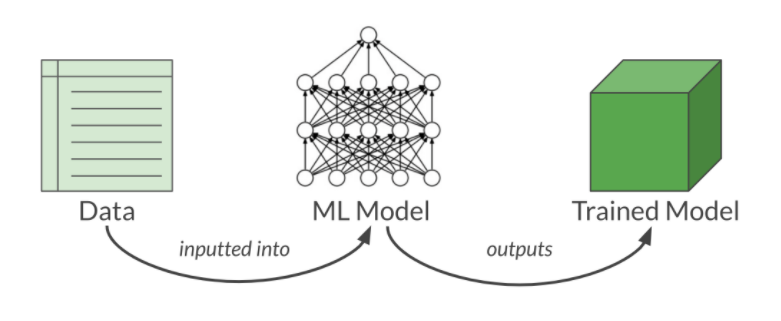
一旦数据集准备好,我们必须将训练数据集输入到模型中,以便它能够学习特征和参数。现在我们可以使用验证集,通过将参数修改到可接受的水平来进一步完善模型。测试集用于测试模型。
在此阶段,学习算法找到输入数据和输出之间的关系并生成一个模型。
到目前为止,我们一直在讨论优化数据以提高模型性能的方法。然而,我们也可以考虑优化模型组件。
在此阶段,使用测试数据集对模型进行准确性和精确度测试。我们使用测试数据集是因为它在训练前未使用过,是全新的,能给出完美的结果。
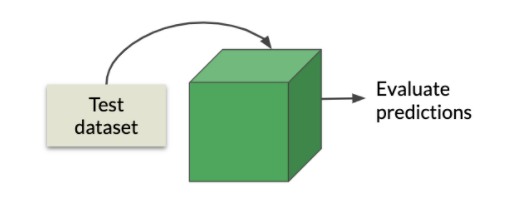
如果模型表现未达到我们的预期,我们可以使用更复杂的参数(称为超参数)重建模型。超参数值控制学习过程。根据所用算法的类型,可能存在许多超参数。
要选择最终模型,我们需要测试每个超参数对模型性能的影响。这发生在模型训练过程中。
一旦我们确定了合适的模型超参数,我们就可以使用测试集评估模型。我们可以看到我们是否需要在此阶段继续调整我们的数据/模型,或者将模型部署为产品。
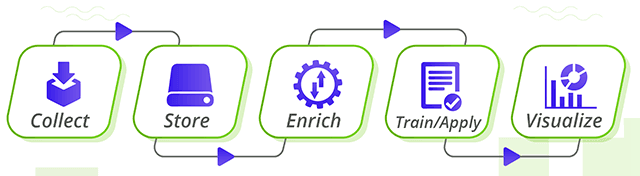
机器学习管道是执行整个机器学习工作流程的自动化方式。管道遵循重要的软件工程原则。在管道中,我们将工作流程部分分解为独立、可重用和模块化的组件。这使得构建模型的过程更加高效和简化。

