

聚类是一种无监督机器学习方法,它将未标记数据中的对象归类到不同的类别中。它可以被正式定义为一种根据相似性将未标记数据分组或分类到不同组别的方法。这意味着聚类将相似的数据点归为一组,而不相似的数据点归为另一组。
聚类如何从未标记的数据集中创建组?这是通过从数据集中发现一些相似性或模式(例如颜色或形状)来完成的。然后,它将具有相同特征的对象归为一组,将其他对象归为另一组,以此类推。
将未标记数据分组到聚类后,每个聚类都会获得一个唯一的ID,以便在处理大量数据集时进行识别。聚类与分类算法有些相似,但聚类作用于未标记数据,而分类作用于已标记数据。通常,这种方法用于数据的统计分析。请看下图以图解方式理解聚类概念。
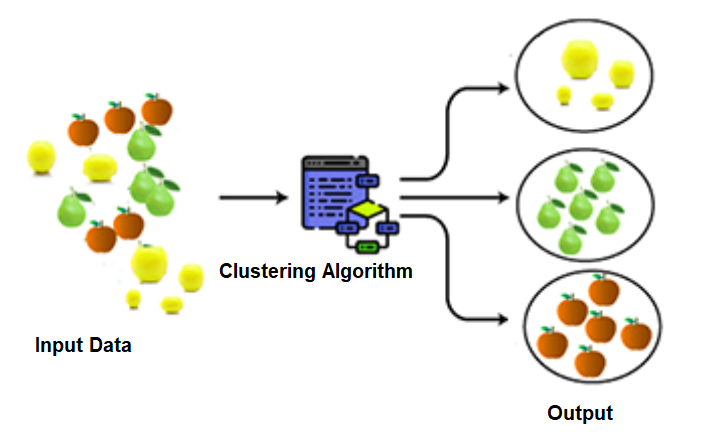
我们可以通过一个真实的例子来学习聚类,假设我们正在逛市场。在市场里,我们可以看到所有商品都根据其相似性和特征进行了分组,例如鱼、不同种类的肉、蔬菜和不同种类的水果等。当商品被分类分组时,我们就能很容易找到所需物品,这是一个完美的聚类示例。
聚类的适用性涉及不同领域,其中一些包括:
亚马逊、YouTube或Netflix等许多领域也使用聚类来对视频进行分类和分组,并提供完美的推荐。它也应用于电子商务公司,用于展示相似产品等。
在一个数据集中,有些对象只能被分到一个组中,这被称为硬聚类。同样,有些数据对象也可以属于其他组,这被称为软聚类。这是广义的分类。让我们逐一检查机器学习中使用的聚类方法。
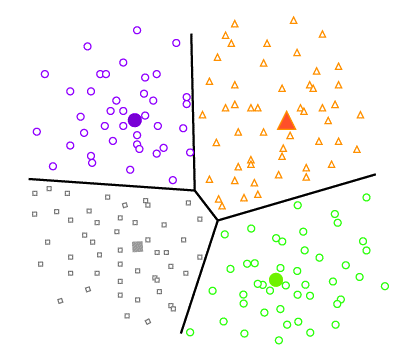
划分聚类也称为基于质心的聚类,因为这种聚类基于一个称为质心的中心点并围绕该质心进行分组。在划分聚类中,数据点被划分为非层次化的组。例如,K均值聚类。
在这种聚类方法中,数据集被分成若干个预定义的组,可以表示为K个组。每个聚类都有一个中心,并且其创建方式使得与该聚类相似的点将比其他聚类中的其他点更接近(最小距离)中心点。
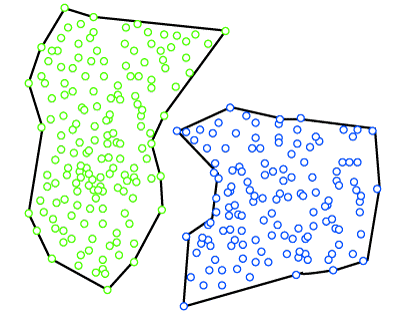
基于密度的聚类是一种根据数据点密度对数据集进行聚类的方法,并将这些更密集的数据点连接成一个聚类。此方法将高密度点连接到一个聚类。
在这种方法中,机器学习算法会找出数据集中所有的聚类,然后将相似特征的密集区域连接成聚类。由于这种密集区域的连接,聚类的形状将是任意的。如果数据集的密度和维度变化很大,这种聚类类型会很困难。
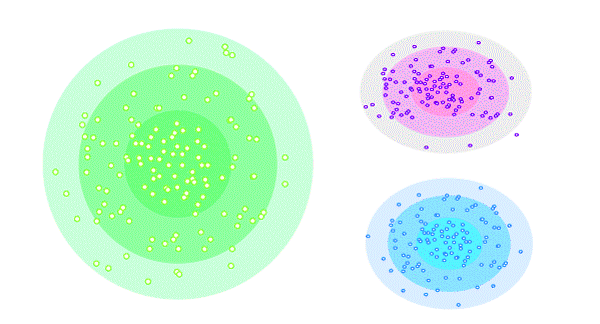
这种聚类方法基于概率,数据根据数据集属于某个分布的可能性被划分为不同的聚类。这种方法通过假设某种分布(称为高斯分布)进行分组。
示例:期望最大化聚类
层次聚类与划分聚类略有相似之处,因此可以作为其替代方法。区别在于,在划分聚类中,我们需要预定义聚类数量,但在这里,则不需要。
在这种聚类方法中,我们知道会创建一个层次树,称为树状图。我们可以通过剪切树状图的不正确级别向其中添加任意数量的观测值。
示例:凝聚层次算法
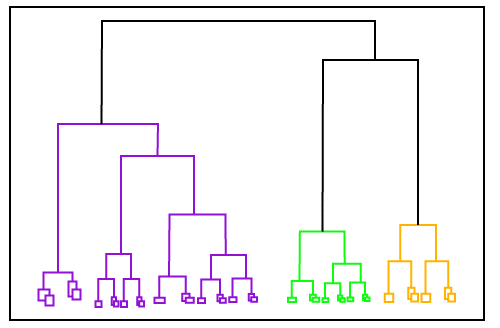
这种聚类类型适用于软聚类。在软聚类中,一个数据点可能属于多个组,因此很难对这些点进行分组。在这里,数据点被赋予一个值,我们称之为隶属度。根据隶属度的大小将点添加到聚类中。
示例:模糊C均值算法或模糊K均值聚类
聚类在应用程序级别有许多用途,其中一些如下所示。
正如我们上面讨论的,有不同的聚类类型,基于这些类型,我们有不同的聚类算法。有许多聚类算法可用,但只有少数是常用的。聚类算法取决于我们需要聚类的数据类型。例如,一些聚类算法需要知道数据集中聚类的数量是多少。一些聚类算法需要知道数据点的距离。
让我们来看看一些机器学习中常用的聚类算法。
K均值聚类
这是最流行的聚类算法类型,目前应用于机器学习。该算法根据方差将数据集分类到不同的组中,复杂度为O(n)。
对于 K 均值聚类,算法需要指定数据集中聚类的数量。
凝聚层次算法:
这是一个层次聚类的例子,它会形成一个树状结构。在凝聚算法中,聚类将以自下而上的方式进行,每个数据点一开始都被视为一个聚类,然后它们会合并到树中。
均值漂移算法
均值漂移算法是基于质心聚类的一个很好的例子,它创建一个中心点,并使所有与该聚类相关的数据点靠近质心。它的作用是使可能成为质心的点位于聚类中心。
亲和力传播算法
这是一种与上述算法不同的聚类算法,因为它不需要提及聚类的数量。在该算法中,数据点在收敛之前在对之间进行通信。这种聚类的问题在于其复杂性,为 O(N2T)。

