

我们已经讨论了监督学习,它分为回归和分类。我们已经在之前的教程中学习了回归和回归方法。现在我们将讨论分类算法。
分类算法基于监督学习原理工作,因为它需要训练数据集来训练模型。在分类算法中,我们根据训练数据集将数据分类到不同的类别中。
例如,我们想要将电子邮件分类为垃圾邮件或非垃圾邮件,或者简单地说,我们必须根据性别将其分类为男性和女性,或者分类为是或否等。
与回归相比,分类算法的输出是不同的,它将是一个使用训练数据集的监督方法来预测输出的类别。分类算法可以用公式表示:
y=f(x),其中 y = 分类输出
通过一个简单的图片,我们可以更多地了解分类,其主要目标是将数据分类到不同的类别中。在下面的图片中,有两个具有不同属性和特征的类别。因此,我们的目标是将具有相似属性的数据分离到一个类别中,将其他相似属性的数据分离到另一个类别中。
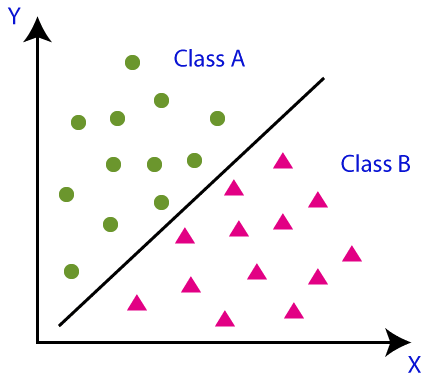
分类可以分为两种类型,在此之前,我们必须理解“分类器”一词。分类器不过是用于数据集中对数据进行分类的算法。
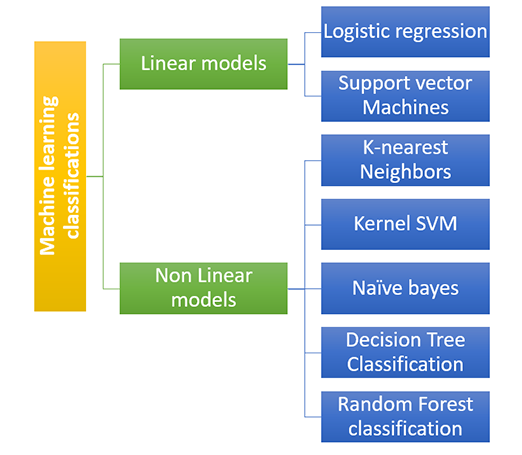
分类算法大致分为两种类型
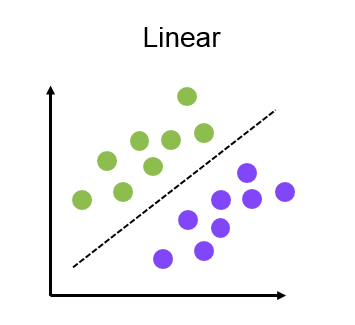
线性模型可以分为
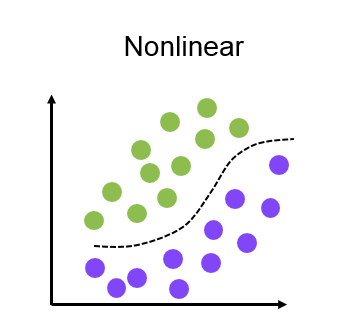
非线性模型有多种类型,包括
顾名思义,在惰性学习器中,训练数据集将被存储,它将等待实际数据输入并进行分类和模型训练。这里的分类基于训练数据集中存储的相关数据。在惰性学习器中,预测需要更多时间,但训练时间更少。示例是 K-NN 算法和基于案例的推理。
主动学习器在获得训练数据集后立即构建模型。它不像惰性学习器那样等待测试数据集。它会在测试数据到来之前构建模型。例如决策树、朴素贝叶斯、ANN 等。
在监督学习中,分类模型和回归模型一旦完成都需要进行评估。在分类模型中,我们有三种评估类型:
这是监督学习方法中用于衡量分类器准确性最常用的方法。我们将数据集分为训练数据集和测试数据集。
之后,我们向模型提供包含数据集及其对应类别的训练数据集。然后模型将通过训练数据集进行学习。然后我们向模型提供测试数据集,其中包含数据集但没有对应的类别。模型必须准确预测测试数据集的类别。
混淆矩阵或误差矩阵将以矩阵形式输出结果,描述我们模型的性能。矩阵的行和列包含简短格式的结果,其中包含正确和不正确的预测数量。查看下面的矩阵以获得一个概念。

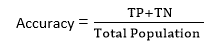
对数损失是一种非常适合二元分类模型的方法,这意味着输出将在数字零和一之间。在这种方法中,我们假设对数损失值越低表示准确性越高,因为如果预测值与真实值之间的差异非常大,对数损失值就会增加。在二元分类中,交叉熵计算为
?(ylog(p)+(1?y)log(1?p))
其中“y”是实际输出,“p”是预测输出

